Can this decision boundary be an example of high bias and high variance?
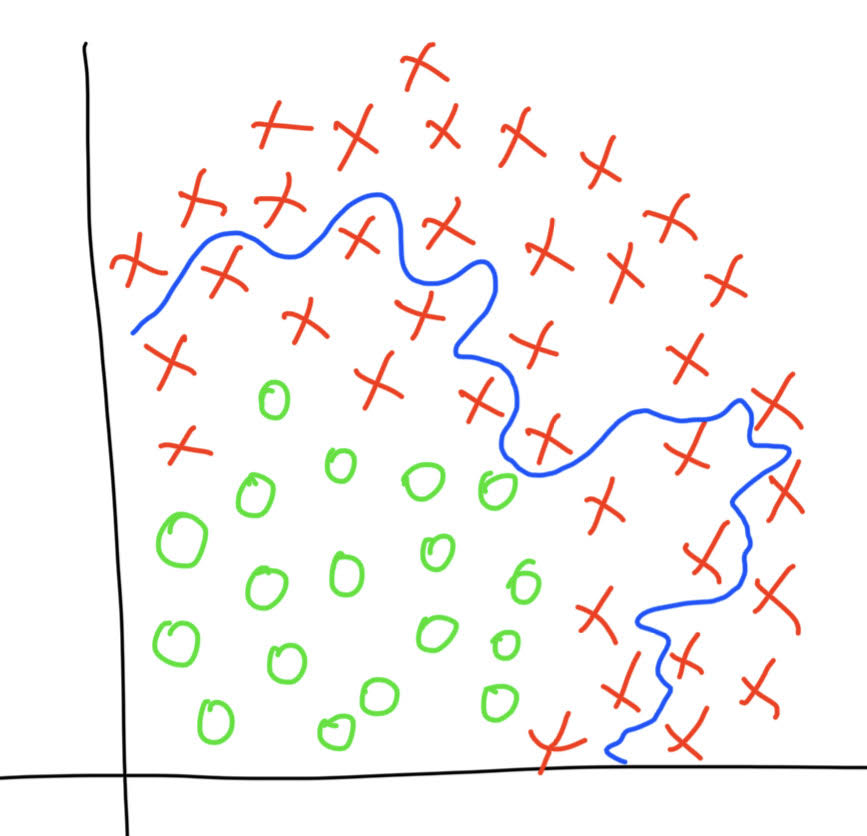
It would help if you specified the training / dev data on seperate plots. The numbers we want to look are the ideal, training and dev set errors.
Assume that we want the model to achieve 0% classification error and the model has 15% training error and 40% dev set error.
Since training error is far greater than ideal error, there is high bias.
Since dev error is far greater than training error, there is high variance as well.
-
The decision boundary isn’t particularly accurate
-
Though the decision boundary has the correct general shape (concave down arc) the line has quite a complex shape.
My understanding is that 1. suggests high bias, a quantification of error, and 2. suggests overfitting and undue influence of the (larger) X population, which means high variance.
But as @balaji.ambresh suggests, when doing actual model training you don’t have guess from looking at a 2 D plot - the training and testing metrics tell you what is going on.