This is a general question about the Adam Optimization Algorithm. Why do we implement bias correction and we don’t in Grad Descent with momentum and RMSprop? Is it because of the major complexity? Or just to get rid of any inconsistencies?
Hi there,
Adam uses the calculation of an exponentially filtered moving average, combining RMSProp and Momentum. At initialisation, usually aggregate gradient is set to 1, meaning they tend to be biased to zero since the averaging parameters are 1. This bias is the reason for the correction, see also this source.
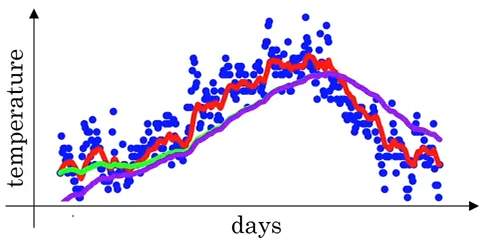
So the purpose of bias correction in exponential filtering is to improve the smoothening of early values, see also this plot (green line: with bias correction): https://napsterinblue.github.io/notes/stats/techniques/ewma/ewma_39_0.png
{kind=link}
In classic momentum or RMSProp we do not have this bias correction, but I agree with you: depending on the initial assumptions of the exponentially weighted moving average, it would be possible in general and it might make sense, see also:
# Momentum
v_dW = beta1 * v_dW + (1 - beta1) dW
v_db = beta1 * v_db + (1 - beta1) db
v_dW_corrected = v_dw / (1 - beta1 ** t)
v_db_corrected = v_db / (1 - beta1 ** t)
# RMSprop
s_dW = beta * v_dW + (1 - beta2) (dW ** 2)
s_db = beta * v_db + (1 - beta2) (db ** 2)
s_dW_corrected = s_dw / (1 - beta2 ** t)
s_db_corrected = s_db / (1 - beta2 ** t)
# Combine
W = W - alpha * (v_dW_corrected / (sqrt(s_dW_corrected) + epsilon))
b = b - alpha * (v_db_corrected / (sqrt(s_db_corrected) + epsilon))
Source: Momentum, RMSprop, and Adam Optimization for Gradient Descent
The Adam bias correction can be interpreted as a modification to the learning rate, see also this paper where an alternative is proposed and discussed:
The originally stated goal of the bias-correction factor was at least partially to reduce the initial learning rate in early steps, before the moving averages had been well initialized (Kingma and Ba, 2017; Mann, 2019).
This thread is relevant for your question. Feel free to take a look: Why not always use Adam optimizer - #4 by Christian_Simonis
Best
Christian