Hi I am getting wrong answers ,can please help to get correct answers

There aren’t that many moving parts here, but the trickiest part is computing the da_next value that you pass to rnn_cell_backward. It’s not just da[:,:,t].

Please have a look at this diagram from the notebook and consider the contents of the green rectangle that I highlighted:

The implication is that the input for the da_next argument to rnn_cell_backward is the sum of two gradients: the one from the path out to \hat{y}^{<t>} and the one coming from the previous step (of course it’s the next step in forward propagation with t + 1, but we’re going backwards here).
Just to complete the picture, look at the left side of the diagram and notice the arrow pointing left there labeled da_{prev}. That is the same as the arrow pointing left into that + sign in the green rectangle at the right side, but that one is from step t + 1. The picture repeats for each time step, but going backwards for back prop.
One hopefully helpful observation is that the “the one from the path out to ^y“ doesn’t actually involve the path that includes (x Way) and (+ by), although the border of green box makes it appear to be one of the two paths that Paul is referencing. After solving this problem, I’m sure that’s not what was intended.
I think I must be missing your point in this comment. There are two “branches” that feed gradients into the computation at each cell: one from the branch out to y_hat and one that is the da_prev output from the previous cell in the sequence. The “branch out to y_hat” is precisely that computation involving Way and by, but we don’t have to do that computation here because we can just call rnn_cell_backward to do that for us. Of course the sequence is running backwards when we do “back prop”, so “prev” here is “next” in terms of forward propagation.
Maybe I’m missing something here, but my focus on was identifying the two components of the da_next parameter of the call to rnn_cell_backward by rrn_backward. Unless I’m mistaken, the calculation flow to y_hat doesn’t make a contribution to either of the two components of da_next, as used in rnn_backward’s call to rnn_cell_backward.
On a related topic, in Exercise 8, there’s a similar question about lstm_backward’s call to lstm_cell_backward, where the composition of the da_next parameter is clear (thanks to Exercise 6), but the treatment of the dc_next parameter of the lstm_cell_backward call is unclear. Exercise 8’s instructions discusses the da_next parameter, but is silent about the dc_next parameter, although it looks like it’s begging for a similar two-component treatment. This lack of a two-component dc_next treatment looks like the most likely explanation for my numbers not working out, but I don’t see a “previous dc_next” in either the cache or the gradient structures. Maybe it’s something else entirely.
For the sake of understanding, since each Backward arrow comes with a Forward arrow, we should know that da[:, :, t] is coming Back down from the Forward path that branches out to y_hat.
In other words, since a^{<t>} branches out to two Forward paths that will both affect the prediction, we expect a Backward path from each of these two Forward paths.
If the function didn’t provide da[:, :, t] , then we might have had Way somewhere in our code, but this might not be your focus, if I understand correctly? ![]()
![]()
Similarly, if we read the graph below, there is only one Forward path out for c_{next}, so we expect one Backward path in.
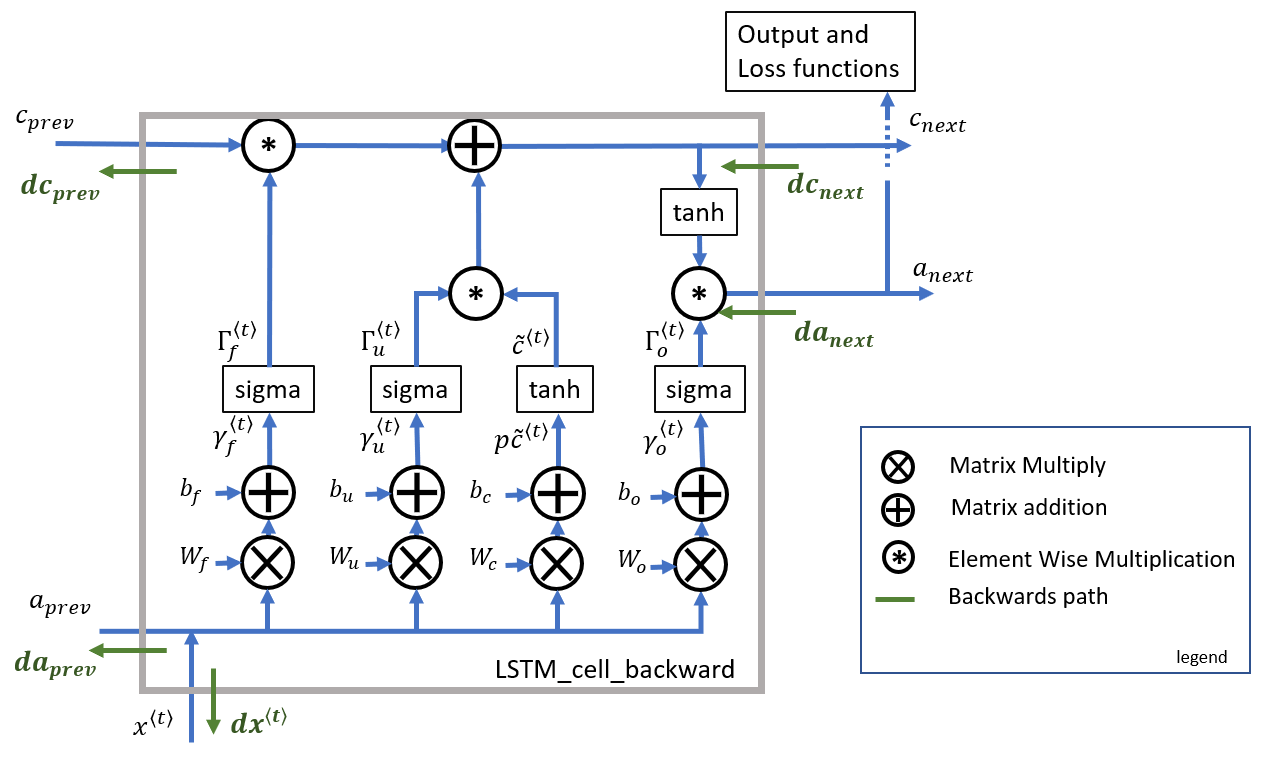
Cheers,
Raymond