I am stuck in the grading exercise with this error. I did some checks and verifications: I believe that this model remains available in togetherai (not deprecated, still listed as part of embeddings models) and that the togetherai API key used in the deeplearning.ai platform seems valid.
without access to the model, no embedding can be generated (most of the exercise and grading steps). I could not find any guidance on this issue in the forum.
how to solve the issue?
Hi! Thanks for pointing out the issue you’re facing. I’m investigating it now and will get back to you as soon as possible.
@veyssier, I tested it on my end and everything works as expected. In the M3 assignment, we use this model locally and do not rely on external API calls. Could you please try again? If possible, please share a screenshot of the error, it would be helpful.
Hi Lucas, very strange indeed… it did not work for several hours today so that I spent several hours this aft adapting to make the whole notebook running locally on my pc using weaviate cloud (very nice) with cohere reranker and weaviate default embedding engine (free cluster).
I just saw your message and retried the notebook on the platform. It is indeed working in full now…. Do not understand why.
Previously the flask app was running, the bge model was downloaded but there was this error each time an embedding was required (semantic_search_retrieve was the first step to fail). I restarted the notebook (and the environment) several times but the error did not go away.
ps: I noticed the notebook seems to use weaviate differently with connect_to_local (client = weaviate.connect_to_local(port=8079, grpc_port=50050)). I succeed implementing the whole workflow with weaviate could but i wonder if I could also this other approach, maybe using ollama / LMStudio for embedding and reranker models. However it seems quite more complex.
- would you happen to have a blueprint for this (local?) approach?
Additionally, I ask myself a question on how weaviate vectorstore / semantic search operates:
- we chunk the main text (not touching title or description)
- in weaviate, the properties include notably the chunk, the title, the desc and the full text looking at the data we are provided
=> what does weaviate use to compute the embedding vector ? the chunk only ? the combination of all properties ? if so, does it still exclude the full text and how ? (otherwise why bother chunking)
=> Do you know the strategy used to prepare the vectorstore ingestion?
- If I know what the emb vector covers, then I can understand which fields are used for semantic search.
would be great if you could shed some light on my above questions. This said, coming back to the initial issue, thanks for your heads-up, everything is now working as expected…
Hi!
In this case, running the notebook locally can be a bit tricky due to the way Weaviate is configured to run within the Coursera environment, which comes with several limitations. We start a local server when weaviate_server.py is imported, and the notebook simply connects to it. This isn’t how Weaviate would typically be used in a production environment, but it’s a practical solution for Coursera: it runs within their environment and keeps things simple enough for learners to understand how to work with a vector database.
Their documentation is pretty good and in a production environment you can just set an OpenAI key to run openai models very easily. There are other methods too.
Regarding the blueprint, I’ll include details on how the database is vectorized (for the assignment) along with the full dataset. Since the dataset is quite large, there will be some limitations on how we can provide it to learners. Once that’s ready, I’ll let you know.
You can use this notebook with any vector database—you’d just need to re-vectorize the entire dataset or find a way to migrate the existing vectors from one database to another.
If a collection is already populated, you can check which properties are used for vectorization by printing the collection:
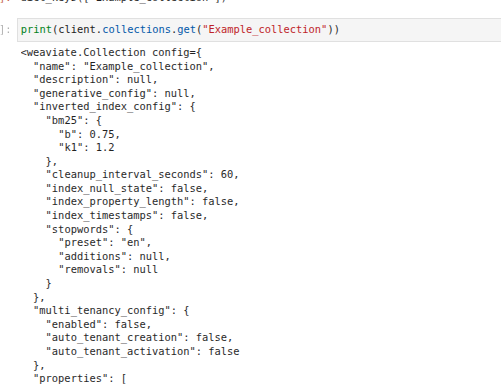
Then, look at the vectorizer configuration:

Essentially, Weaviate concatenates all the source properties (separated by spaces) and runs an embedding model on the resulting string. In this setup, the embedding model is defined when connecting to the Weaviate server:

In the Weaviate ungraded lab, we demonstrate how to vectorize a dataset. You can specify which properties are used for vectorization here:

And here’s the general setup for a collection:
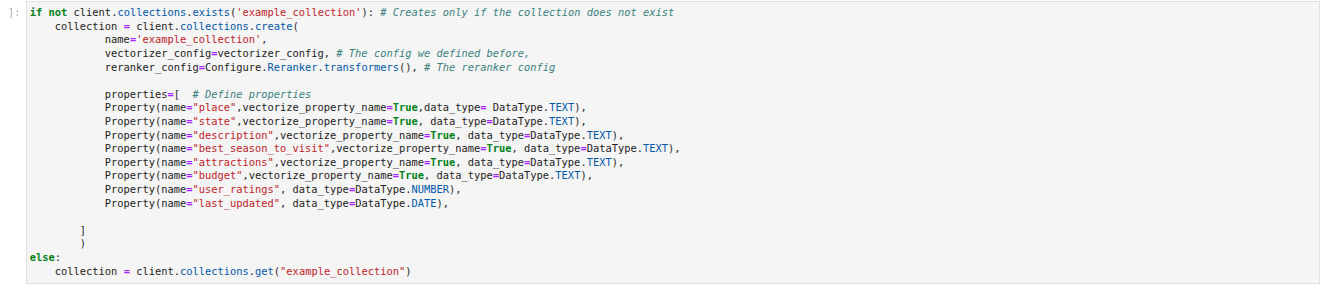
The process is handled by the transformers_inference_api, which runs on the flask_app.py server. This isn’t a production-scale setup—Weaviate offers much simpler and more robust Docker-based approaches—but due to Coursera’s environment constraints (and for clarity), we had to implement it this way.
Throughout the course, we use the BAAI/bge-base-en-v1.5 embedding model, as shown in utils.py:
![]()
I hope this clarifies things! Let me know if you have any other questions.
Would you like me to make it slightly more formal (for internal documentation or email to a colleague) or keep it casual and conversational, as it currently is?
thank you for your detailed answer. I figured out already all what you are mentioning but there are still 2 areas where I am unclear.
1/ How to proceed for a locally-hosted implementation approach.
2/ the ingestion strategy (and chunking step).
As for 1/, I replicated the workflow using a free cloud cluster and ended up with 155.279 vectors in the db. I use weaviate default embedding model instead of openai model and cohere reranker you can also set up. Using their cloud platform is very solid, flexible and convenient indeed.
As previously mentioned, I initially thought of a local set-up because of ```connect_to_local (client = weaviate.connect_to_local(port=8079, grpc_port=50050))``` found in the notebook exercise, but it looked complex and not the default approach channelled by the weaviate docs.
I think I now understand from your explanation that this local setup adopted by Coursera seems rather a pragmatic choice for convenience than the go-to approach. Would you confirm there is indeed not much interest in trying to do a local set-up ?
The free cluster is valid for 14 days and gets wiped out afterwards. A locally-hosted solution could be handy on occasion. This is the blueprint I am looking for with a clear, local db set-up workflow. I might look again into weaviate_server.py and see if I can find the how-to there.
As for 2/, I gained a better understanding of weaviate principles regarding properties used for vector calc, metadata and query.near_text / flltering. I used certain assumptions to come to the 155.279 vectors and made choices regarding property definition leading to the vectors. I am not clear whether this is the ideal approach and would be keen to compare to the approach used by Coursera.
Here is my set-up :
Chunking step :
source_text = bbc_data[2][“article_content”]
chunks = get_chunks_fixed_size_with_overlap(source_text, chunk_size = 50, overlap_fraction = 0.2)
I assembled chunks leaving out the full text article_content (which seems however still attached to each chunk in Coursera vector db):
chunk_obj = {
"pubDate": *doc*\["pubDate"\], "guid": *doc*\["guid"\], "link": *doc*\["link"\], "title": *doc*\["title"\], *# title* "description": *doc*\["description"\], *# description* "chunk": c, *# The actual chunk of text* "chunk_index": i, *# The index of the chunk in the list* *#"article_content": doc\["article_content"\]* }
ingestion step:
These chunks were added to the weaviate collection using:
collection = client.collections.create(
*name*="bbc_collection", *vector_config*=Configure.Vectors.text2vec_weaviate(), *# Configure the Weaviate Embeddings integration* *reranker_config*=Configure.Reranker.cohere(), *# using default reranker "rerank-v3.5"* *properties*=\[ # vectorize_property_name= False by default Property(*name*="title", *data_type*=DataType.TEXT, *description*="Title of the article", *skip_vectorization*=False, *module_config*={"text2vec-weaviate": {"skip": False}}), Property(*name*="description", *data_type*=DataType.TEXT, *description*="Description of the article", *skip_vectorization*=False, *module_config*={"text2vec-weaviate": {"skip": False}}), Property(*name*="chunk", *data_type*=DataType.TEXT, *description*="Chunk of the article", *skip_vectorization*=False, *module_config*={"text2vec-weaviate": {"skip": False}}), Property(*name*="chunk_index", *data_type*=DataType.INT, *description*="Index of the chunk", *skip_vectorization*=True), Property(*name*="pubDate", *data_type*=DataType.DATE, *description*="Publication date of the article", *skip_vectorization*=True), *# metadata* Property(*name*="link", *data_type*=DataType.TEXT, *description*="Link to the article", *skip_vectorization*=True, *module_config*={"text2vec-weaviate": {"skip": True}}), Property(*name*="guid", *data_type*=DataType.TEXT, *description*="Guid of the article", *skip_vectorization*=True, *module_config*={"text2vec-weaviate": {"skip": True}}) \])
Would be good to compare with the definitions used by Coursera (chunking parameters, collection properties configuration…). Additionally, I have “source_properties”:null in my vector_config unlike your provided example (showing a list of fields coming from the weaviate walk-thru notebook). Is my approach correct and optimal?

Also, I get the summary below which contracicts that it should have used the first 3 properties only for the emb. vector calculation. Again, not sure I use the correct property definitions syntax.
schema = client.collections.export_config(‘bbc_collection’)
for prop in schema.to_dict()[‘properties’]:
print(prop\["name"\], prop\["moduleConfig"\])
title {'text2vec-weaviate': {'skip': False, 'vectorizePropertyName': False}} description {'text2vec-weaviate': {'skip': False, 'vectorizePropertyName': False}} chunk {'text2vec-weaviate': {'skip': False, 'vectorizePropertyName': False}} chunk_index {'text2vec-weaviate': {'skip': False, 'vectorizePropertyName': False}} pubDate {'text2vec-weaviate': {'skip': False, 'vectorizePropertyName': False}} link {'text2vec-weaviate': {'skip': False, 'vectorizePropertyName': False}} guid {'text2vec-weaviate': {'skip': False, 'vectorizePropertyName': False}}
Hope my remaining points are clearer and that you may be able to clarify them.
many thanks
note that i use the latest weaviate SDK version which can explain some differencies in syntaxt