Hello,
I have a question regarding the correct way to handle one-hot encoding for new prediction data, specifically in Step 6 of our process.
1.This image shows the raw test in test_cars.csv using for prediction. noted the Fuel type column: the first three records have type ‘X’, and the fourth has type ‘Z’.
2.This image shows the result of X_test_multi after this raw data is run through the prepared preprocessing pipeline. The issue is in the Fuel_type_X column. It is incorrectly populated with all zeros. Given that the input Fuel type for the first three rows is ‘X’, this column should have a value of 1 in those rows.
This seems generating an unreliable predictions ?
Pls help to clarify me on it , Thanks~
2 Likes
Dear @jacko99,
You’re right, the predictions are unreliable because the one-hot encoding is incorrect.
Issue:
- Fuel type ‘X’ appears in rows 1–3, but
Fuel_type_X is 0 for all.
- This likely happened because the encoder used during training wasn’t reused for the test data.
Fix:
- Fit encoder on training data only, and reuse it for test data.
- Use
OneHotEncoder(handle_unknown='ignore').
- Wrap preprocessing and model in a single pipeline to ensure consistency.
Let me know if you need help fixing the code.
Hello, @jacko99,
Nice catch. The reason behind is that, when we call pd.get_dummies, we set the parameter drop_first=True, and because the test set has only X and Z as the values, the column for X was dropped, but then we call fuel_type_dummies_test.reindex to add it back with its value filled with 0.
I agree, and I think that’s a bug.
@jacko99,
- As far as this assignment is concerned, I believe this shouldn’t fail your submission but if it did, please let us know here.
- In practice, it would be better to use alternatives like
sklearn.preprocessing.OneHotEncoder, or we still use pd.get_dummies but do the dropping ourselves.
@chris.favila, please take a look at this case.
Cheers,
Raymond
1 Like
@jacko99, I have filed a report to the course team. Thanks for sharing this.
Dear @Girijesh
Thank you for the quick and clear confirmation. That makes perfect sense.
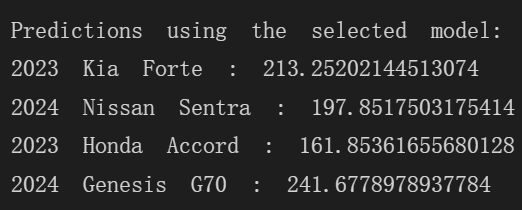
I’ve already updated the code to reuse the same fitted OneHotEncoder, and I’m now getting the prediction results.
Appreciate the guidance!
1 Like
Dear @rmwkwok
Thank you for the detailed explanation. That clarifies why the re-indexing caused the bug.
I can confirm that I have now used sklearn.preprocessing.OneHotEncoder as you suggested, and it gives me the predictions.
Thanks for your help!
2 Likes
You are welcome, @jacko99!
Cheers,
Raymond
Great work @jacko99. Keep learning.
Thank you!
Hi, and thank you for reporting! Good catch! The code for Step 6 has been updated for new learners taking the assignment.
2 Likes