Can someone please help me understand this:

The question is is (i) in c(i) the index of the training example x, or the centroid c?
The reason I ask is because later on Andrew writes:
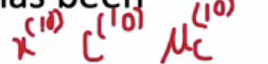
… which indicates that the indexing of x(i), c(i), and mu_c(i) are all the same.
The image in the first photo makes sense to me, the second one does not.
Thanks.
Hello @Rod_Bennett,
I need some clarifications:
-
At what time mark(s) of which lecture video(s) did you see the first and the second photo?
-
You said the second one indicates that the indexing are the same, is it because they are all (10)? But the first photo show that they are also the same because they are all (12). Where is the critical difference between the two cases?
-
Why the first one make sense but the second does not?
Raymond
Hello @Rod_Bennett,
Thank you for the clarifications!
The i in the superscript means the i-th training example. You are right that the number of centroids should always be less than that of the examples. The following slide explained the meaning of the symbols:
The only thing that I am not certain about is your following comment:
because the second picture didn’t say anything about “there are more centroids than examples”. Particularly, if you watch 1:28 to 2:00 again where the three symbols in the second picture were first introduced, Andrew was just repeating the definitions of the symbols without even saying how many centroids there were in total.
Therefore, I am still not certain about where you got the impression that there were more centroids than examples in the second picture.
Btw, if I were to rewrite the symbols, I would place that superscript lower:
x^{(10)} means the location of the 10-th sample
c^{(10)} means which cluster the 10-th sample belongs to
\mu_{c^{(10)}} means the location of the c^{(10)}-th cluster
Cheers,
Raymond

