My first question is:
Do we first use CV to decide the degree of the polynomial (assuming its a polyonym that we need)
and then λ, or perhaps we try all combinations (all meaningful) of d \times λ .
Second question is:
Is the example presented in the videos (specifically Model selection and training/cross validation/test sets, week 3) a 1-fold CV example?
Third question:
After tuning our parameters w and b with the dev set (finding the minimum J_{cv}(w,b) ), we just use these parameters to calculate the J_{train}(w,b) cost. Am I right? The training of the model in that regard takes place on the dev set, and train data is just for seeing how well we did with w,b obtained? Or does another round of training/fitting the model is happening on the train data set as well (CV is only used on dev set , we get d and λ and the only thing we keep is the model’s degree and lambda and not the (\vec{w},b) obtained by fitting on the dev set data)?
Final question:
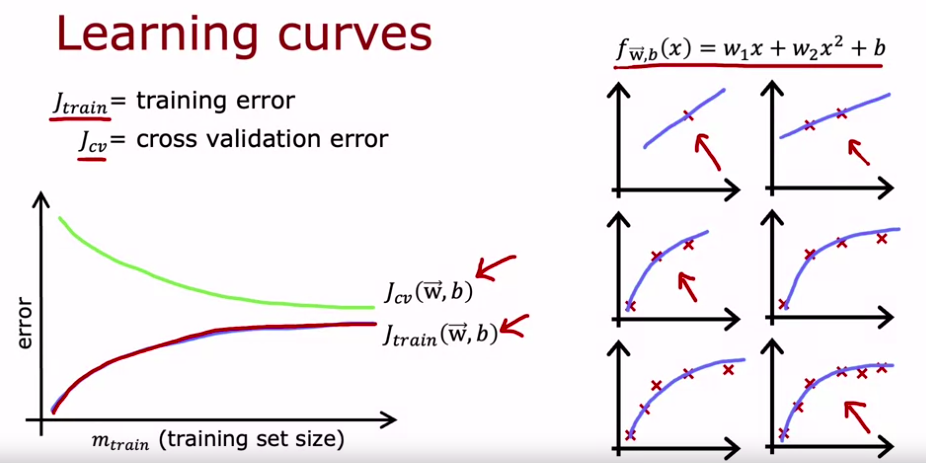
In the video Learning curves(week 3) , how is J_{cv}(w,b)
related to the training set size (I am really messed up by this, I expected the number of examples of the dev set to be relevant here)?
J_{cv}(w,b) is decreasing when the train data is growing but do we use (\vec{w},b) obtained by fitting the dev set or just d and λ? And why does the professor showcases the different polynomials for the J_{train}(w,b) , I thought that the degree should have already been decided by J_{cv}(w,b). Here , I would expect the train error to rise and converge , but not being almost zero initially (as shown in the picture ) when the size is small.
Because of this slide, my perception is that we first work with dev set data to select the model, and then we estimate the generalization error, using the test set but with the \vec{w},b obtained by the dev set data.
Then we fit this model to the train data and receive new parameters \vec{w},b.
Perhaps then, I can understand how the J_{cv} is reduced when the m_{train} gets larger, and is large when the number of train examples is low.
Hello Kosmetsas, it’s good to see that you are making progress!
Yes! We train each combination with the training set, then evaluate the trained model with a cv set. We compare the cv performance of each combination and pick the best one.
Yes!
Not really. We train the model parameters for each combination by the training set to achieve the minimum J_{train}(w,b). Then we used these parameters (or the trained model) to calculate the J_{cv}(w,b).
P.S. we don’t necessarily have to use the cost function J for evaluating the model, but using the cost function is completely fine, so J_{cv}(w,b) is fine. Let’s stick with this to avoid confusion.
No, explained in (1) and (3).
The process is explained in (1) & (3). I just want to mention that “cv set” is “dev set”. “cv” is cross-validation, which is a process for you to validate your choice of model (e.g. choice of \lambda and the degree of polynomial).
Here we consider that the size of cv set is fixed, and we only change the training set size.
Remember, as pointed out in (1) & (3), that we always train our model with the training set, and we only validate the model with the cv set.
The argument is: as we increase the training set size, the model should generalize better to unseen data (which means to cv set), so the error J_{cv} should drop.
In the above slide, professor always considered only one model assumption, which is what he underlined in the top right corner. There is no process of comparing different model assumptions, just one and only one here. The 6 graphs are showing the change of the fitted line as we add one more training sample at a time to the training set. (I will continue in (8) because it will be addressing your last question)
Initially, when there is only one sample in the training set, the model can fit perfectly to the sample, and because it is perfect, the J_{train} is zero. It remains at zero as we add the second sample and the third sample to the training set. However, as we add the 4th samples, the model starts to not be able to fit perfectly to each of the training set samples, and so J_{train} starts to grow.
Let me know if you still have any confusion, Kosmetsas.
I hope my above explanation (1) is enough for you to connect the dots between using training set, using cv set and model selection, but if not or if you just want to check your understanding, please let me know.
Cheers.
Raymond
P.S. Sometimes you might see people re-train their model with both training set and cv set after they selected a model using steps explained in (1). In my (1), such retraining isn’t included, and if I remember correctly, Professor’s videos also didn’t include that. That step is not necessary, but it is also seen as a way to improve the training result of the selected model because you can say “Hey, now I selected the model already, cv set is no longer needed, let’s combine cv set with training set to form a bigger training set, and use it to train a better version of the selected model!”. Such motivation makes complete sense, right? But I mention this here in P.S. because again, this is NOT included in the video and is not necessary. However, just in case you had seen people “re-train” models after cross-validation and caused you any confusion, therefore maybe it’s better for me to talk about it here as well.
Thank you very much for your explanation and time, I think I understood.
As a student, I would love to have an example that lists ( for educational reasons only) a strict
and ordered set of actions. Perhaps a snippet of code would be nice.
But your answer definitely helped me do that.
ps: I am a Mathematician so when I see a line ( I think first order polynomial) . I am referring to the top two graphed axes.
ps2: If I undestood what you said correctly, J_{cv} should generally fall and converge as m_{train} gets bigger, but does not necessarily have to be large initially (if the offchance, the first untrained element of dev set falls right on top of the 2nd order curve. These things destroy me!
You are welcome Kosmetsas! This sklearn page explains in very detailed what cross-validation is and, as you can expect, code examples of using sklearn to do cross-validation. Let me know if you have any question!
But J_{cv} sums over all samples in the cv set, so for it to be small initially, we need to be very lucky that most if not all samples falls right on top of the 2nd order model (I prefer to use model here because it does not have to look like a curve =P, thanks for bearing with me).
I like discussing with Mathematician, and I will remember you are one Look forward to your next thread!