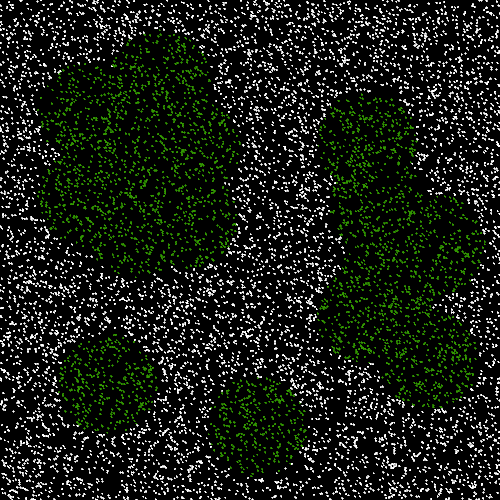After finishing the first three courses in the specialization, I decided to revisit course 1 and make my own offline NN script, in my own environment (VS Code).
The neural network code is completely copied from the code we get in the Jupyter notebooks.
For my first practice project I decided to create a model to map 2-D Vectors to 0/1 classes.
Training set (10,000 examples, green = 1, white = 0)
Test set (10,000 examples)
My model’s layers_dims is [2, 4, 1] and it is unable to learn at all, it always predicts 0. I have no idea how to proceed.
Any advice?
I am not attempting to do any input normalization, momentum, mini-batching, weight initialization, because all those things seem like optimizations that I should not need at this point, since this seems like it should be a simple model to train.
I’ve tried multiple layers_dims, adding more layers and more nodes per layers, changing the learning rate too. It just seems like this model can’t learn
It’s great that you are trying to adapt the code to solving a new problem. You always learn something useful when you do that.
If none of the layer structures that you have tried ever predicts any output other than 0, I would expect there is some fundamental problem here. E.g. maybe there is something different in your environment that causes things not to work or maybe you didn’t port the code correctly to your new environment. One way to figure this out would be to try a problem that you already know works in your new environment. E.g. take the dataset from the Planar Data exercise in Week 3 and the same network architecture and see if you can duplicate the results from the Week 3 exercise in your environment.
Reporting back:
After lots and lots of tweaking, it turned out my code was fine, and that the answer was really just increasing the hidden layer node amount
I thought 5 to 7 was enough because that was enough in the assignment, but results were much better at n[1]=15 or above.
I also learned that tanh seems to work much better than relu for this model. Relu was more likely to get stuck during learning, and when inspecting the parameters and gradients, it seems that sometimes the gradients are mostly zero. I’m assuming that its because when Z is negative the gradient is 0 for relu, and things don’t move along. Tanh is slower than relu though.
Another thing I learned is that normalization (0-mean, unit-variance) is more important than I thought, it seems necessary with this project, which surprised me, because I don’t understand why. Also, not normalizing meant that often I’d get NaN issues, or just just completely non-working models (always predicting 0)
Very cool! So it sounds like you learned a bunch of useful things through this exercise. Yes, normalization is surprisingly important: it makes the gradients work much better. It’s especially important in cases in which the various features have different ranges, which doesn’t seem like it would be the case in your example. But still it can matter.
It’s also a good observation that ReLU can have vanishing gradient problems. The other experiment you could try would be using Leaky ReLU, which should fix the vanishing gradient problem.