import sys
from datetime import datetime
from awsglue.context import GlueContext
from awsglue.dynamicframe import DynamicFrame
from awsglue.job import Job
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.conf import SparkConf
from pyspark.context import SparkContext
from pyspark.sql import functions as F
from pyspark.sql.types import *
# Take a look to the `args` object with the parameters requried to run the job
args = getResolvedOptions(
sys.argv,
[
"JOB_NAME",
# The Glue Catalog database name
"catalog_database",
# The date when data was ingested, formatted as your current date in Pacific Time (UTC -7) to match the server's timezone
"ingest_date",
# Object's path in the source Data Lake
"source_bucket_path",
# Object's path in the destination Data Lake
"target_bucket_path",
# Name of the songs table inside the Glue Catalog Database
"songs_table",
],
)
# Take also a closer look to the `conf` object, which corresponds to the underlying Spark's configuration
# Some additional configurations have been added in order to allow the Glue Job to save data into Apache Iceberg format using the Glue Catalog
conf = SparkConf()
conf.set(
"spark.sql.extensions",
"org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions",
)
conf.set(
"spark.sql.catalog.glue_catalog", "org.apache.iceberg.spark.SparkCatalog"
)
conf.set(
"spark.sql.catalog.glue_catalog.warehouse",
f"s3://{args['target_bucket_path']}/transform_zone",
)
conf.set(
"spark.sql.catalog.glue_catalog.catalog-impl",
"org.apache.iceberg.aws.glue.GlueCatalog",
)
conf.set(
"spark.sql.catalog.glue_catalog.io-impl",
"org.apache.iceberg.aws.s3.S3FileIO",
)
sc = SparkContext(conf=conf)
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args["JOB_NAME"], args)
spark.conf.set("spark.sql.sources.partitionOverwriteMode", "dynamic")
ingest_date = args["ingest_date"]
date_object = datetime.strptime(ingest_date, "%Y-%m-%d")
ingest_date_str = date_object.strftime("%Y_%m_%d")
# Script generated for node Amazon S3
source_bucket_path = args["source_bucket_path"]
# The `landing_node` object corresponds to the creation of a Glue Dynamic Frame by reading the data from the `landing_zone`
landing_node = glueContext.create_dynamic_frame.from_options(
format_options={
"quoteChar": '"',
"withHeader": True,
"separator": ",",
"optimizePerformance": False,
},
connection_type="s3",
format="csv",
connection_options={
"paths": [
f"s3://{source_bucket_path}/landing_zone/db_songs/ingest_on={ingest_date_str}/"
],
"recurse": True,
},
transformation_ctx="landing_node",
)
# Script generated for node Amazon S3
# The Dynamic Frame is converted into a Spark's Dataframe with the `toDF()` method
df = landing_node.toDF()
# Enforce schema
df = (
df.withColumn("duration", df.duration.cast("float"))
.withColumn("artist_familiarity", df.artist_familiarity.cast("float"))
.withColumn("artist_hotttnesss", df.artist_hotttnesss.cast("float"))
.withColumn("year", df.year.cast("int"))
.withColumn("track_7digitalid", df.track_7digitalid.cast("int"))
.withColumn("shs_perf", df.shs_perf.cast("int"))
.withColumn("shs_work", df.shs_work.cast("int"))
)
# Add Metadata
# For this script, the only transformation that you are going to add is the creation of a new column named `"ingest_on"`
# Use the `withColumn()` method to create that column
# Use the `F.to_date()` and `F.lit()` PySpark functions applied over the `ingest_date` object to convert it from string into date
df = df.withColumn(
"ingest_on", F.to_date(F.lit(ingest_date), "yyyy-MM-dd")
).withColumn("source_from", F.lit("postgres_rds"))
catalog_database = args["catalog_database"]
songs_table = args["songs_table"] # songs
target_bucket_path = args["target_bucket_path"]
tables_collection = spark.catalog.listTables(catalog_database)
tables_in_db = [table.name for table in tables_collection]
songs_table_exists = songs_table in tables_in_db
if songs_table_exists:
print(f"Appending data to table {songs_table}")
df.writeTo(f"glue_catalog.{catalog_database}.{songs_table}").tableProperty(
"format-version", "2"
).partitionedBy("ingest_on").append()
else:
# Create (equivalent to CREATE TABLE AS SELECT)
print(f"Creating table {songs_table}")
df.writeTo(f"glue_catalog.{catalog_database}.{songs_table}").tableProperty(
"format-version", "2"
).partitionedBy("ingest_on").createOrReplace()
job.commit()

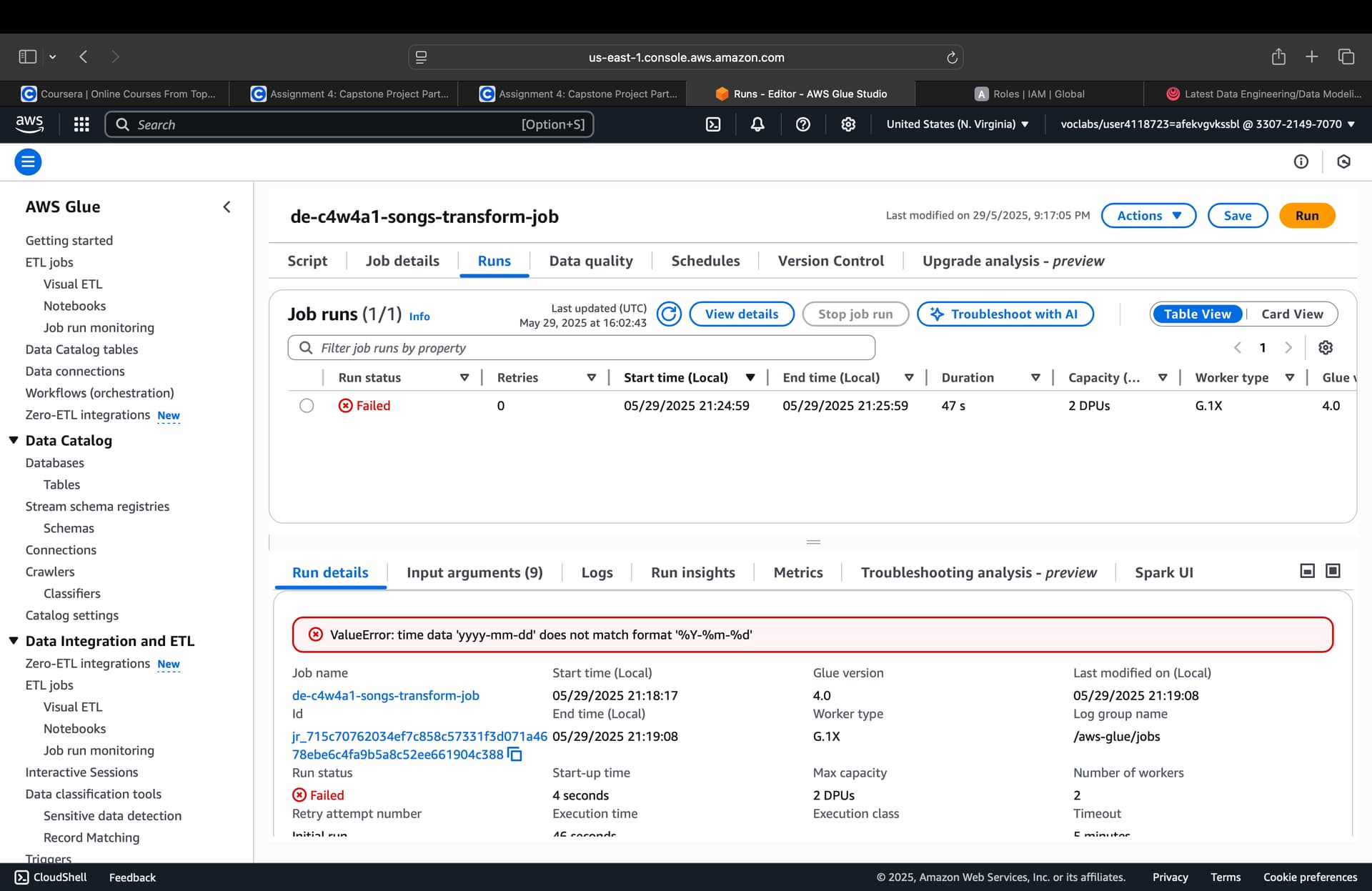
I am getting error while running transform-job-songs.py glue script it’s giving me value error.
please help