Hi, I’m doing the optional lab C1_W3_Lab06_Gradient_Descent_Soln.
I noticed that you implemented compute_gradient_logistic() function using nested loops, however it would be much more efficient if you used matrix multiplication, wouldn’t it?
So I implemented a “vectorized” implementation, that you may find here, which looks 10 times quicker on your server:
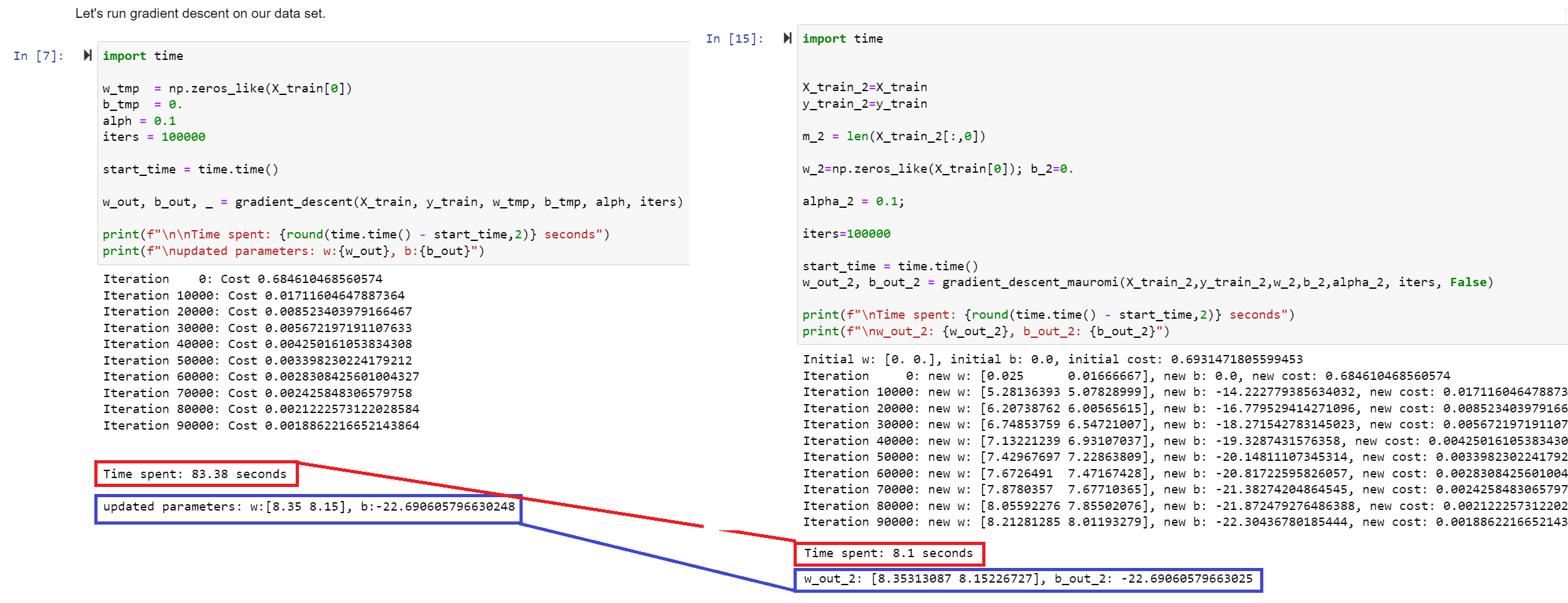
If you find it useful, please feel free to share my implementation, I’d be very glad if you may just mention me. Thank you!
Mauro