Loss in Andrew’s course is computed by measuring the difference in vertical height between the ground truth target label and the algorithm’s prediction.
But wouldn’t it be faster and more accurate to measure’s perpendicular distance from the ground truth label to the algorithm’s prediction ?
Computing the perpendicular distance It is computationally more expensive, and the industry feels it does not provide enough benefit to be worth the extra CPU cycles.
No, not simpler. But the ground truth label is likely to be closer to the initial prediction by measuring perpendicular distance than measuring vertical drop.
So perhaps fewer iterations or epochs as the prediction starts out closer to the label than the current linear regression estimate.
It would be interesting to perform an experiment and see how expensive loss computation is for computing perpendicular distance against vertical drop distance.
The last expression is undefined at 0. You can make an experiment comparing the execution time in the loop. I suspect that the time difference will be negligent.
is a very good approximation to the original expression.
The reason that I looking into this is to find out if the gradient descent algorithm can be made to work faster in a linear regression problem by using perpendicular distances from the ground truth labels to the model’s predictions.
Mine for your reference. This should avoid heavy-lifting being optimized away because all results are different and kept. Another test could be comparing the run times of your model training before and after your approximation.
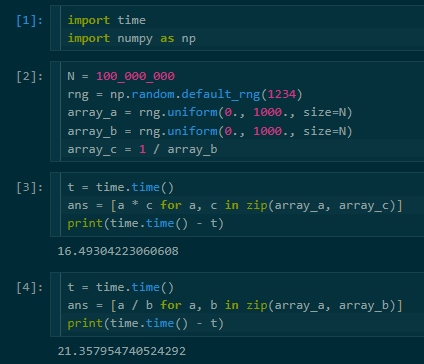
Floating-point multiplication is faster by 3.67%.
[ps@localhost ~]$ python ex_op_speed.py
Floating-point multiplication: 49.680842 seconds.
Floating-point division: 51.764723 seconds.
Please note, such test gives only rough estimates due to several reasons:
Modern CPUs dynamically adjust their frequency based on workload to save power and reduce heat. If your benchmark starts running while the CPU hasn’t yet ramped up to full speed the first iterations may execute at lower frequency. You may want to add a warm up step before measuring.
Most likely, Python is optimizing the expressions you compute by precomputing the result:
I suggest to make a different computation at each step, e.g. a *= 1.00000001.
3. Other processes run by OS might affect the results. Add more iterations and run the test multiple times.
One more thing: Python adds overhead that can drown out the real cost difference between the operations. If you want to benchmark raw multiplication vs division, you can use C/C++ or, as Raymond @rmwkwok suggested, is to use NumPy (after all you will end up using it for your model implementation).
I have a question about Apple Silicon. I want to replace my 2015 MBA with something more powerful. How is the overall performance? Have you experienced CPU/GPU throttle under high loads such as models training?