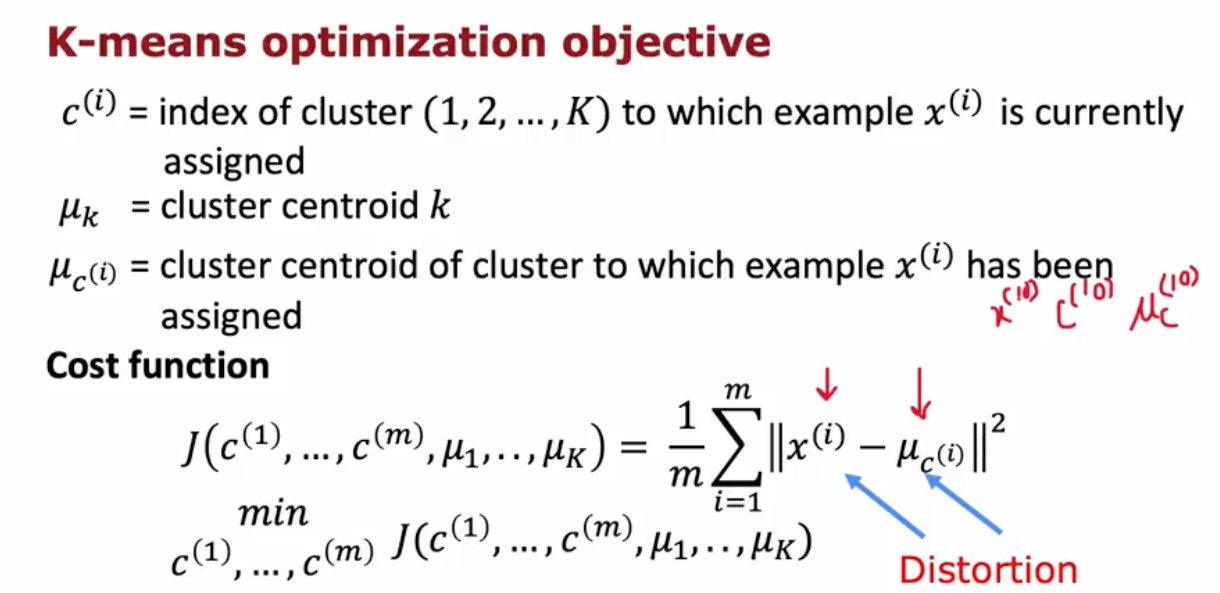
Your question is not clear to me. I’ll still try to answer as far as possible. m represents the total number of data points we have and for each of such data points there’ll be cluster index (so indirectly a cluster centroid) assigned to them.
We compute the error from each data points, as we did for the supervised learning, to obtain the cumulative error. And Error from each data here is defined as the L2 norm distance of each data point to its corresponding cluster centroid.
Hope it helps!
-Hari
Hello @vinooj, could you be more specific about which part of this slide has a problem? The slide didn’t say there were m clusters, instead it said there were K clusters.
I was getting little confused about the J(c(1)…c(m),µ1…µk). I was under the impression if there are m cluster indices, then there will be µm centroids as well.