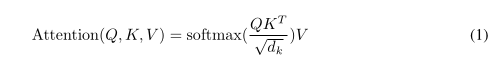In the self-attention mechanism, when computing the query vectors (Q), why do we use separate linear transformations for each step (Q = dot(W^Q, X) and Q_1 = dot(W^Q_1, Q) instead of just using a single linear transformation (Q_1 = dot(W^Q_1, X))? Isn’t the first method still a linear transformation of X, which is equivalent to the second method? It seems redundant to have multiple linear transformations. What are the benefits or justifications for this approach?
The figure is shown below for better understanding what I’m trying to ask here (Assume the embedding dim = 512, and projection_vector_dim = 64)

If you are still struggling to grasp the concept of why the combination of two linear transformations resembles a single linear transformation, try to imagine a deep neural network operating without any activation functions