Is there a general rule of thumb that can help me choose the size of the network from the size of the dataset? Currently I have 3600 sets of data and I want to train a network directly with these data. How big should I set it up?
The number of examples doesn’t determine the best model.
The number of features might, though.
Sir can you help me clarify the difference between features and examples? Should my network size be correlated to the feature size?
Which courses have you attended? That will help me know what level of answer will be most useful.
I have completed DLS Course and currently using a CNN.
The difference between features and examples was covered in nearly every week of the DLS CNN course. This is a fundamental concept in machine learining.
I recommend you review the lectures in DLS C4 W1.
1 Like
Hey @Chiang_Yuhan,
On top of @TMosh answer he is right you need to review the lectures. I will just give you a brief clarification but don’t forget Tom’s advice ![]()
Well so “features” are the characteristics or attributes of your data that you use to make predictions or classifications. “Examples” are individual data points or instances in your dataset.
let’s consider an example involving the classification of fruits. In this scenario, the features and examples would be as follows:
-
- Color: This could be a feature that describes the color of the fruit (e.g., red, green, yellow).
-
- Size: The size of the fruit, such as small, medium, or large, is another feature.
-
- Weight: The weight of the fruit in grams could be a numerical feature.
-
- Texture: The texture of the fruit’s skin, which could be smooth or rough, is another feature.
-
- Shape: The shape of the fruit, such as round, oblong, or irregular, is a feature.
Examples, on the other hand, are individual instances of fruits with associated values for these features. Each example represents a single data point in the dataset.
For instance:
- Example 1: A red apple that is medium-sized, weighs 150 grams, has smooth skin, and is round in shape.
- Example 2: A green pear that is large-sized, weighs 200 grams, has a rough skin, and is pear-shaped.
- Example 3: A yellow banana that is small-sized, weighs 120 grams, has a smooth skin, and is elongated in shape.
I hope it’s more clear for you now.
Regards,
Jamal
1 Like
That description assumes that your input data is the sort of categorical descriptions of attributes of the fruit that you gave in some form equivalent to a spread sheet. In the case that the input is images of fruit, then the input features are simply the pixel values of the image. For example, if the images are 64 x 64 x 3 RGB images (64 x 64 pixels each of which has three color values), then you have 12288 features.
1 Like
And it gonna be different when it comes to Text or even Audio so i guess he should provide us about what type of data he’s asking about ![]()
1 Like
I mainly use vibration data from different channels which I could either convert into a matrix or a picture.
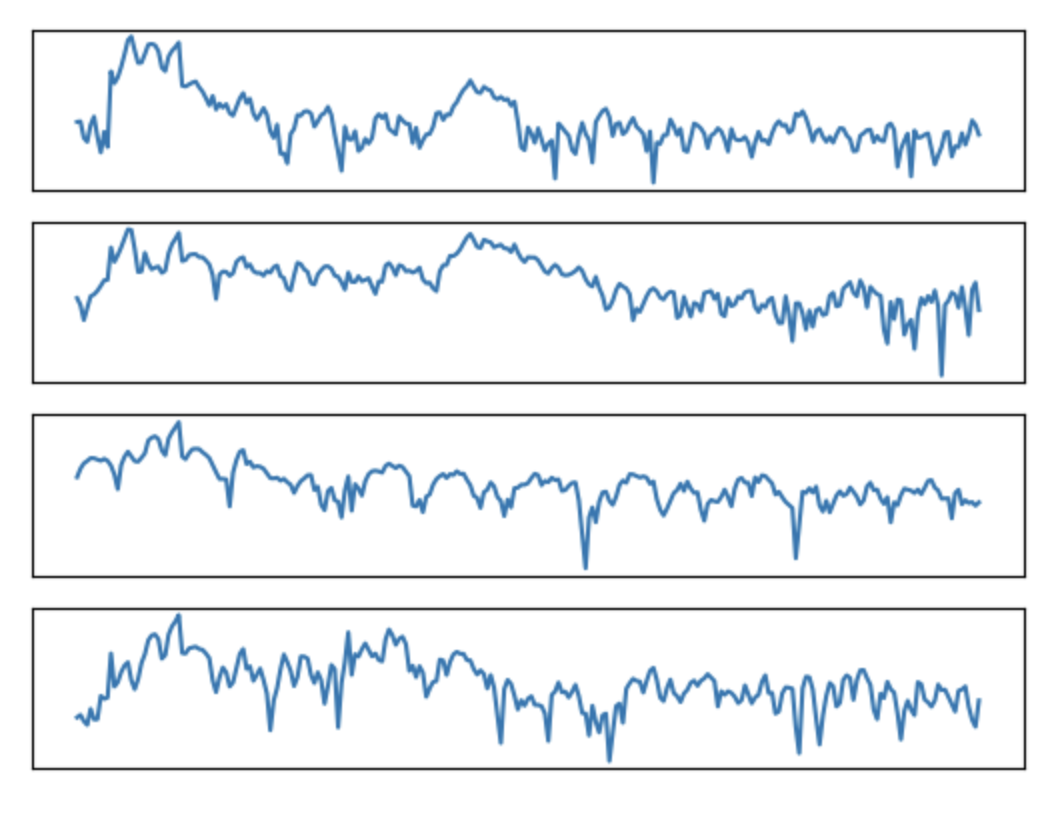
I presume the vertical axis in you images is the magnitude of vibration.
What is the horizontal axis (time or frequency)?
What do you want the model to do? What are the outputs?
Sir the vertical axis is the magnitude of the Fourier Transform Signal. The Horizontal axis is the frequency all until the nyquist frequency.
I want my model to conduct a classification task with 6 classes (all classes has almost the same amount of examples)
The image size or feature size that I input in the 8 layer network is (160 x 160 x 3) or 76800 in total. My neural network has 3500 trainable parameters.
I am struggling to see any size (160x160x3) images here. Is each of those traces a separate image? Or is that one image with four traces?
It doesn’t appear you’re making any use of the color palette, why is it a 3D image?
How did you arrive at 8 layers? A simple image classification task most likely doesn’t need eight layers (and will struggle to be trained effectively).
Yes the traces are separated images. Here is an example of my image:
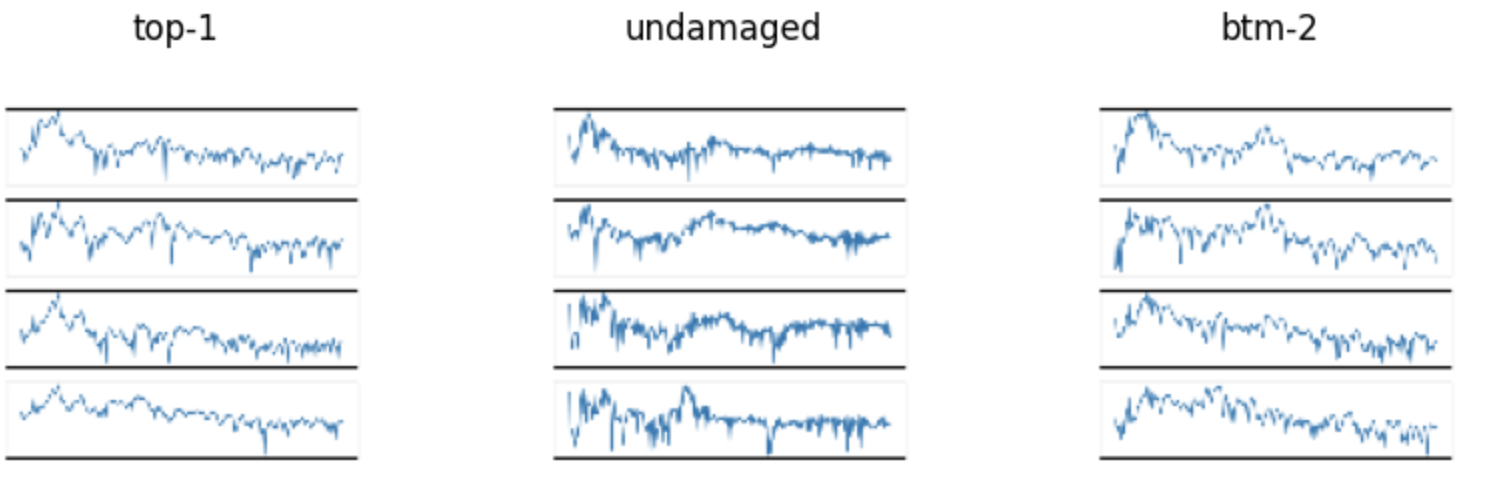
Also here is a summary of my model. I count 8 layers.

Pardon me for asking, but your images do not appear to be the size you state. Can you give some evidence that the images are size (160 x 160 x 3)?
Why do you feel you need to use an 8-layer deep network for this?
Did you do some tests first using just a simple NN with one dense hidden layer and an output layer with six units?
Is 8 layer considered deep for a task with 3600 cases?
I downsized the images to 160 x 160.
I haven’t done tests for a simple NN with one dense layer.
Thanks for the reply!

Yes, 8 layers is a lot.

Well, the ReLU activations aren’t really “layers” in that they’re activation functions. Nothing to train there.
And “input” doesn’t have anything trainable either.
So you’ve got two conv layers, two max-pooling, and a dense.
That doesn’t seem too bad.
1 Like
Is this the same model you’re asking questions about in two other threads?
It would be nice to keep this discussion all in one place.
1 Like