I don’t think my work has problem. Why it’s incorrect? I guess if the corpus is changed, the expected output should be adjusted as well.
# UNQ_C8 (UNIQUE CELL IDENTIFIER, DO NOT EDIT)
# GRADED FUNCTION: compute_accuracy
def compute_accuracy(pred, y):
'''
Input:
pred: a list of the predicted parts-of-speech
y: a list of lines where each word is separated by a '\t' (i.e. word \t tag)
Output:
'''
num_correct = 0
total = 0
# Zip together the prediction and the labels
for prediction, y in zip(pred, y):
### START CODE HERE (Replace instances of 'None' with your code) ###
# code removed - not allowed by the code of conduct
### END CODE HERE ###
return num_correct/total
If you print out word_tag_tuple, you can see it contains noises. I used strip to remove unwanted characters before the split, and split is based on ‘\t’
Thanks for your reply.
However, I don’t think tuple() function will change original length. Actually I followed youe advice and change the line to
word_tag_tuple = y.strip().split(’\t’). I got the same result as before. Can I ask in your work how many num_correct did you get in your work?
Well, sorry, in that case, I don’t see this part has problem…
my output is:
num_correct: 31311
total: 32853
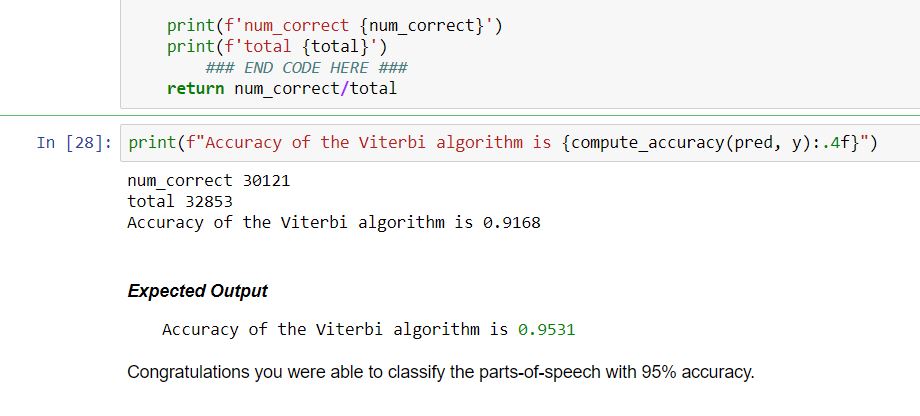
Accuracy of the Viterbi algorithm is 0.9531
I am getting an accuracy of 0.9168.
I see that another person on this list also got this. Was this issue ever resolved? i.e. how to get 0.9528?
My “viterbi_backward” → method has some issue. Is the above problem of 0.9168 due that? I.e. unless you get “Viterbi_backward” correct, you can’t get the method “compute_accuracy” correct?
Hi, I am getting the stated 0.9531 accuracy instead of 0.9528 if I give correctly the pos_tag_for_word_i variable in viterbi-backward function as per instruction