I got the following error on the above mentioned programming exercise (input code is shown below). I see some similar errors in the discussion that might be related to global variable misuse. If it is that problem, could I get a clear example of how that might affect me in this exercise?
The following is the input code in the notebook cell:
Build a model with a n_h-dimensional hidden layer
parameters = nn_model(X, Y, n_h = 4, num_iterations= 10000, print_cost=True)
ValueError Traceback (most recent call last)
in
19 #print(“num of iterations”,num_iterations)
20 # Plot the decision boundary
—> 21 plot_decision_boundary(lambda x: predict(parameters, x.T), X, Y)
22 plt.title("Decision Boundary for hidden layer size " + str(4))
~/work/release/W3A1/planar_utils.py in plot_decision_boundary(model, X, y)
14 # Predict the function value for the whole grid
15 Z = model(np.c_[xx.ravel(), yy.ravel()])
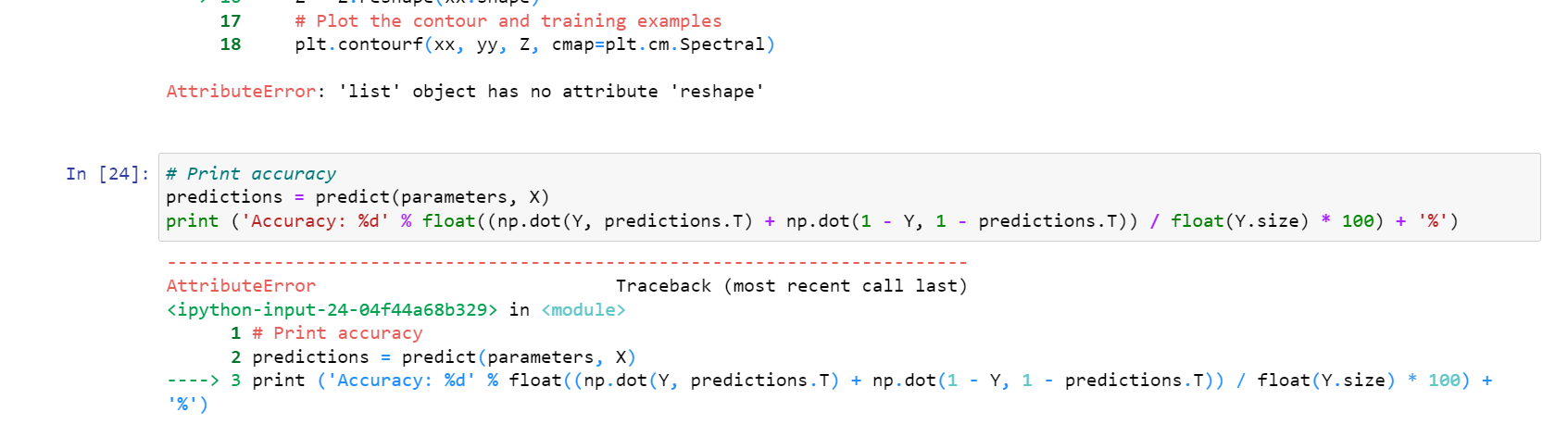
—> 16 Z = Z.reshape(xx.shape)
17 # Plot the contour and training examples
18 plt.contourf(xx, yy, Z, cmap=plt.cm.Spectral)
ValueError: cannot reshape array of size 3 into shape (1008,1030)
If you don’t have the assignment of cache in the predict function by calling forward_propagation, then that is the classic example of referencing a global variable: cache is not defined in the scope of your original predict function, so you have no idea whether the values are relevant to the particular call to predict you happen to be making at the time. In the case of the test case for predict, apparently you get lucky and they happen to have loaded cache earlier with the appropriate values. I’d call this a bug or at least a deficiency in the test case in the notebook. I’ll file a bug about it. I have seen that particular error in plot_decision_boundary before from other students and never understood what would cause that, so I can add this to my list of “gotchas”. Thanks!
reshape() is a function. To reshape an array to a different shape, you have to give it the new size in a tuple. Here is a link to the reference menu.
So it would look like this:
Z = Z.reshape((3,4))
Note that the error is being thrown in code you didn’t write and that code is actually a bit complicated, but the best way to debug this is to track backwards through that code from the point of the exception to figure out why you passed an incorrect value to that code. Note that the value Z in that expression is supposed to be a numpy array, but somehow it ends up being a list. That is what that exception is telling you. Now you need to figure out where the Z came from and why it is wrong.
If you look just a bit at that code, what you see is that Z is the return value of your predict function. So that is where to look for the problem: why would the return value be a list? Are you sure your predict function passed the test in the notebook?
Great! That probably means you had typed in new correct code, but had not actually executed the cells containing the changed code. If you just call the function again, it runs the old code. You can easily demonstrate this behavior: type in wrong code in a function that is currently working and then call it again from the test cell. It still works! Now click “Shift-Enter” on the function cell with the new broken code. Then run the test again and “Kaboom!”
Hello Sir, I encounter with same error "AttributeError: ‘list’ object has no attribute ‘reshape’ ". But, I scored the assignment 88/100. My predict function passed the test. But I can’t troubleshoot the error in 5.2. Here is predict function test output.
The error “throws” in code that you didn’t write, but now you need to track backwards to figure out why the values you passed to that code triggered the error. Based on your previous post, my guess is that the type of the return value from your predict function is incorrect. Notice that your output doesn’t completely match the “Expected Output” for predict. The values are correct, but the format is not. Try adding another cell after the normal test case for predict (use “Insert → Insert cell below”):
Ok, that’s the cause of the problem. Now you need to figure out why the type is wrong. It should be a numpy array. There are two ways to implement predict:
We could use a for loop as we did when we implemented predict in the Week 2 Logistic Regression assignment. In that case the template code they gave us created the predictions output as an array of zeros and then we fill in one element in each iteration of the loop.
We could use the more efficient and sophisticated approach that they showed us as a “hint” in the instructions for this function: you can do direct boolean comparisons between a numpy array and a scalar value and it gives you back a numpy array with the “elementwise” result of the comparison.
If you use either of those methods, then the output value naturally is a numpy array.
You must have used concatenation or some other technique in your code, which causes it to be a list.
Hello Sir, sorry to bother you this much. Now , the type was changed to numpy array, but the prediction values are different from Sir’s code snippet above. Additionally, the accuracy result is very much lower than the expected output.
Surprisingly, My Grade score of the assignment changed to 100/100. But am in trouble for my low accuracy result.
If I miss something, awaiting your awesome advise.
Your answer on the predict test case looks correct. It’s fine to leave them as Boolean values, instead of coercing them to “float” which is how I did it. Are you sure you get “All tests passed!” on predict now?
For the other thing with the 54% accuracy, are you sure you ran the full training again first? You might have been picking up a stale value of X or parameters. Because the grader gives you 100%, my guess is that your code is actually correct, but the state of the notebook is not consistent. One way to make sure that’s not the problem is to run everything afresh like this;
Kernel -> Restart and Clear Output
Cell -> Run All
Then scan through and see your results. I’ll bet you get 90% accuracy after that.