Hello, @suresh359,
I think there are 2 points that we may want to pay attention to:
1
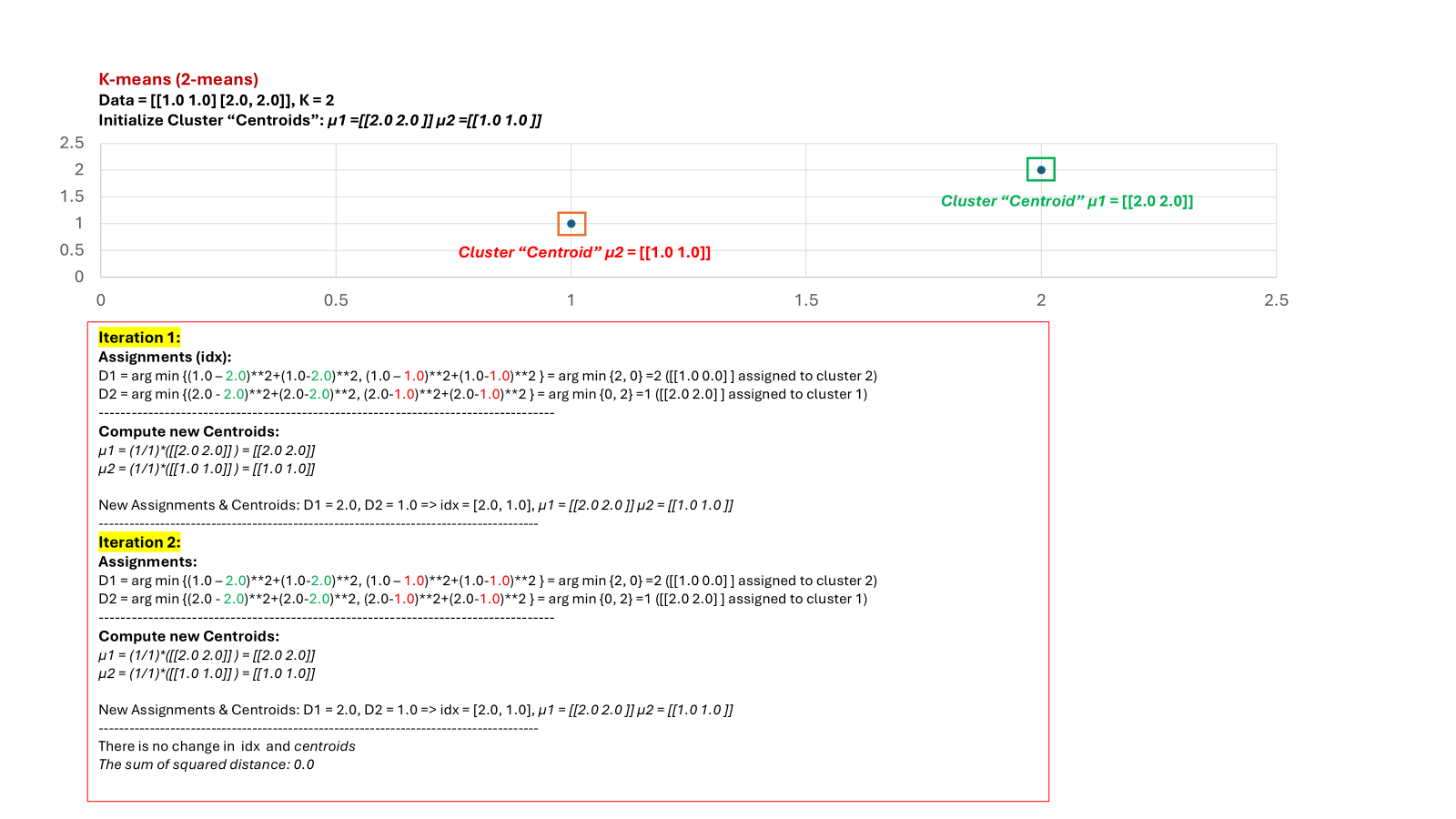
I read page 249 of Flach’s book: Machine Learning: The Art and Science of Algorithms that Make Sense of Data and it does not say “zero” as the value of any local minimum.
To disprove something, we only need one counter-example. Therefore, to disprove “zero”, we can look at the following counter-example when there are two data points and k is set to 1.
In this case, the sum of squared distances can never be zero no matter where we put the centroid at. In other words, there is local minimum, but that local minimum cannot always be zero.
2
I have searched the book on K-means (from page 247 to page 252) for the word “convex” and it never shows up.
I think there is a reason that we might not want to discuss “convex” in K-means.
“Convex” is a geometric idea, so when we say “convex”, we need to know it in our mind that what space we are thinking about.
For example, for
, the loss is convex in the space of
\hat{y}.
Another example, for linear regression, which is
, the loss is convex in the space of
w and
b.
You see, the full description should be "the loss is convex in the space of some dimensions
Now, what is the full description on convex for k-means? What are the dimensions that the loss is (or is not) convex in?
For linear regression, we choose w and b because they are the trainable parameters. For K-means, what are the trainable parameters? In other words, what are the things that are being trained to change? I am going to write them below but as a workflow:
Now, I want to emphasize that the thing that we calculate the sum of squared distance (data point’s cluster ID) is not a continuous dimension. If it is not a continuous dimension, we cannot differentiate it. To prove the loss convex along a dimension, we show the 2nd derivative (with respect to that dimension) positive at the location that the 1st derivative is zero. However, because now it is not differentiable at all, we cannot prove it this way with differentiation.
In fact, as I said before, to disprove, you only need a counter-example, and so the book actually tried to deliver an example which is on page 249.
In conclusion, I would like to suggest that, when you study K-means,
- to disprove it is convex, you need only a counter-example;
- there is no need to use calculus or derivative of any function you call it loss to see if it is convex. “Convexity, calculus, derivatives” are concepts usually bounded together in many discussions, but for K-means, I don’t really think the set is relevant.
Cheers,
Raymond