Hi, I have an issue with the function tester, as I am getting the expected result
But having this issue with the “# Test your function” section
What should I do? as I can not change anything in this section.
Hi, I have an issue with the function tester, as I am getting the expected result
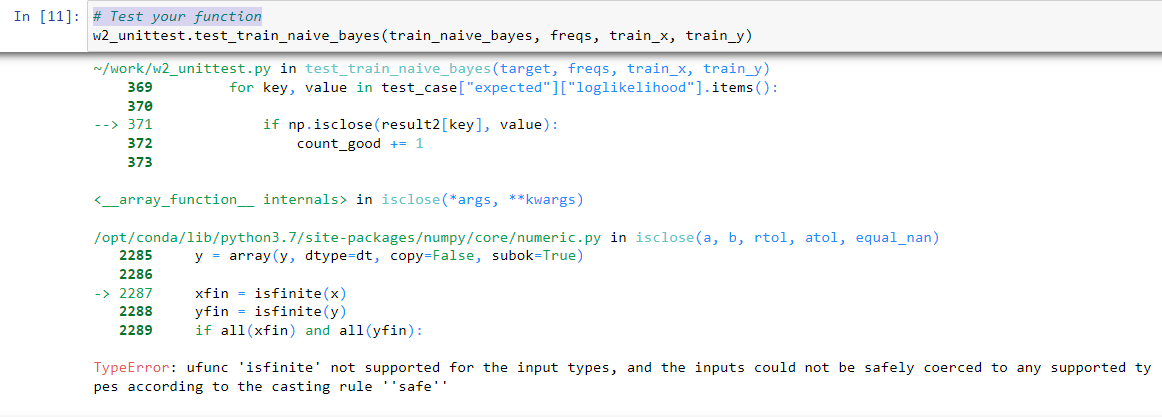
The point is not that you need to change the test code: the failure of the test is telling you that something is wrong with your code. There must be some value your code is producing that is an array, when it should be a scalar.
You can read the test code to understand more about how it works and perhaps that will help translate that error message into some clue about which value it is that is wrong. You can find the test function by clicking “File → Open” and then opening the file w2_unittest.py.
My reading of the code you can see in the exception trace is the problem is most likely that each individual value that you are storing in the loglikelihood dictionary is a numpy array instead of a scalar. Try doing something like this in your code to see:
print(f"type(value) {type(value)}")
I, too, have a question about this assignment. I keep getting the following error message:
Wrong number of keys in the loglikelihood dictionary. Expected 9165. Got 11406.
Any thoughts about what I might be doing wrong? I can share part of my code if needed. Thanks for any help!
It sounds like you added all the words without checking whether they are already in the dictionary. Note that a fair number of them have both a positive and negative sentiment entry, although some have only one or the other. Your logic needs to take that into account. They give you a hint in the instructions to use the python set() function to reduce the list to the unique words.
I added some additional print statements to my logic to show more of the details of what is going on. Here’s what I see:
V = 9165, len(wordlist) 11436
V: 9165, V_pos: 5804, V_neg: 5632, D: 8000, D_pos: 4000, D_neg: 4000, N_pos: 27547, N_neg: 27152
freq_pos for smile = 47
freq_neg for smile = 9
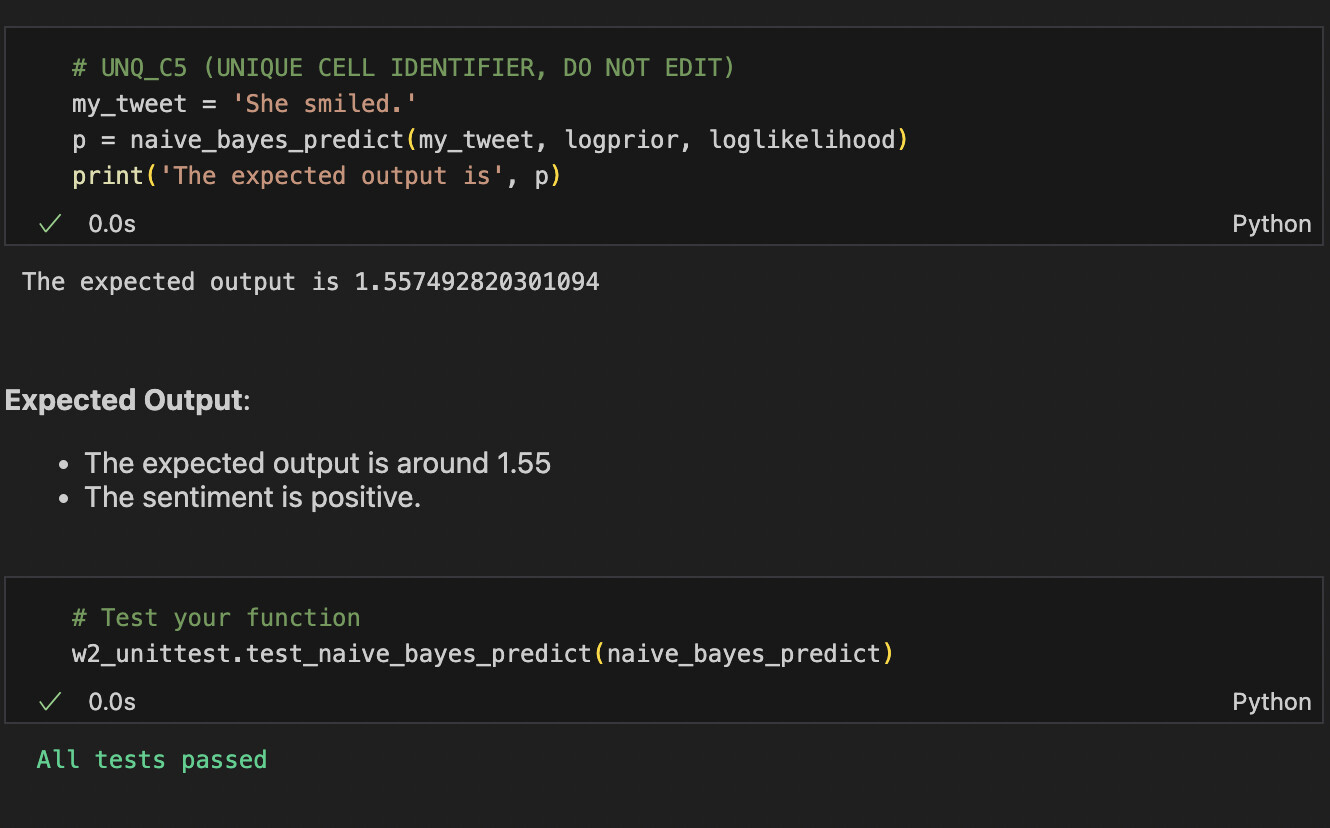
loglikelihood for smile = 1.5577981920239676
0.0
9165
Thank you for your quick response! I am good to go on this assignment ![]()
Hi Paul,
Just want to be sure if I understand the intended use of set() as you indicated.
First, vocab should be derived from freqs dictionary and its keys are tuples of (word, label),
meaning same word occurs twice, once for each label.
Applying set() on freqs only changes the resulting type to a set and in this case retaining only the
key tuples from freqs. It doesn’t return a set of unique words since the original key tuples still
carry the label.
The reason I want to clarify is that I hope I am not over reading that as we meant to achieve the
expected output with one single line of code, ie: vocab = ?
I still need a loop and 2 lines to achieve the expected outcome but no Python expert here of
course.
Thanks,
MCW
The point is not that you apply set() to the entire freqs dictionary as is: the entries are all unique if you consider them as tuples, right? So exactly as you say, you just end up with a set of tuples of the same size. The point is that you want the unique words, right? So first you extract the dictionary keys, each of which is a 2-tuple of (word, sentiment). The keys() method is useful for that and you can use a python “list enumeration” to extract just the words. Then you create a set of the words, resulting in only the unique words.
That will probably end up being two lines of code, although you could write it as one. Minimizing the number of lines does not always yield the clearest code, but that is (of course) a subjective judgement. The grader does not really care about what your code actually looks like: it only evaluates the results. So you can always take those suggestions about numbers of lines as just that: suggestions, not requirements.
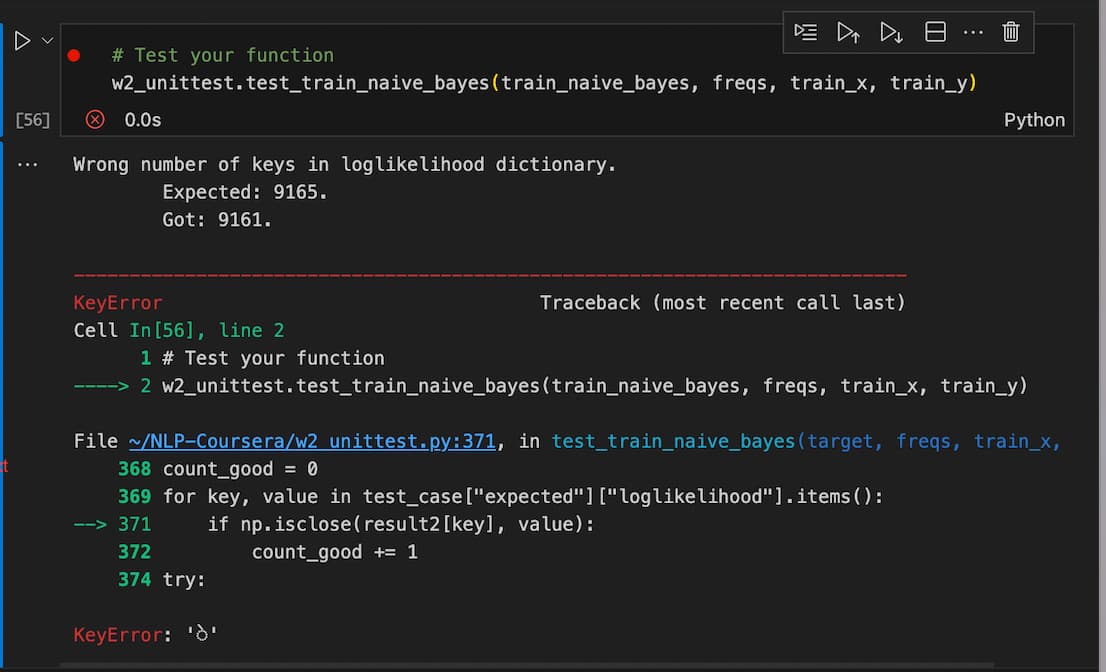
I am facing a similar issue with my assignment. So after I code the train_naive_bayes(freqs, train_x, train_y) function and then print(len(loglikelihood)) gives 9161.
Once I run the unit test on it , it gives the below error:
What am I doing wrong here ?
My variable V (unique words from vocab) also comes out to be 9161.
There must be something wrong with your train_naive_bayes logic. Notice that it’s using a test case with a key that looks like some non-letter character. So there must be something wrong with how you are constructing the list of unique words. I added some diagnostic print statements to my logic to give some visibility into what’s happening and here’s what I see:
type(wordlist) <class 'list'>
V = 9165, len(wordlist) 11436
V: 9165, V_pos: 5804, V_neg: 5632, D: 8000, D_pos: 4000, D_neg: 4000, N_pos: 27547, N_neg: 27152
freq_pos for smile = 47
freq_neg for smile = 9
loglikelihood for smile = 1.5577981920239676
0.0
9165
It looks like you are missing 4 “words” for some reason.
This is my code change section in the function. What am I possibly doing wrong, that it is missing 4 words ?
{moderator edit - solution code removed}
My log likelihood does come out to be same for “She Smiled” as expected in the assignment
Notice that you never eliminated the duplicate words, caused by the fact that some words have both a positive and negative frequency. You used “set”, but only in computing the value of V. You did not use it in computing the value of vocab itself, although you sort of compensate for that by how you wrote the main “for” loop that computes the loglikelihood. But somehow it doesn’t quite end up the same … I’m not exactly sure I can explain why your result is different, but the code is definitely different than the way I wrote it. You will be handling some words twice in the main loop, but I can’t explain why 4 words are missing.
Actually I tried writing the code your way and it worked for me and I did not have the missing 4 words. Are you sure that you still get the same results with the code you showed? You might try restarting your notebook to make sure everything is in sync and the code you are seeing is what you are actually running. E.g.:
Kernel → Restart and Clear Output
Save
Cell → Run All
Then check and see if your train_naive_bayes test case passes.
This is funny and still unexplainable to me. So how I approach these assignments is by copying all Jupyter assignment notebooks, utils.py, support_files etc to my local folder and play with them first in my visual studio virtual environment, and then once everything
goes well, copy the codes in the actual assignment - the web instance of the Jupiter notebook.
On my Visual studio environment, it still shows 9161 (even after kernel restart and rerun of everything)
Whereas when I run it in the actual assignment - the web instance of the Jupiter notebook, it gives me 9165, and the unit test passes.
Have you faced this before, and any possible explanation on it ? ![]()
Thanks anyway, for running this for me on your environment and confirming it worked as expected.
Also thanks for your quick and engaging responses.
I have successfully completed and got graded for the 2nd assignment.
Keep me posted if you get any answer, or anyone posted a similar problem dealing with Jupiter notebooks on IDEs like visual studio
There is no guarantee of things working the same way in a different environment. You face potential differences in versions of APIs and what if your language settings are different? Remember that the error was on something that didn’t look like normal ASCII characters.
It’s good news that things work correctly in the course environment. Your code is not as efficient as it could be, but it generates the correct results which is always the highest priority item in any case. We can worry about performance later. ![]()