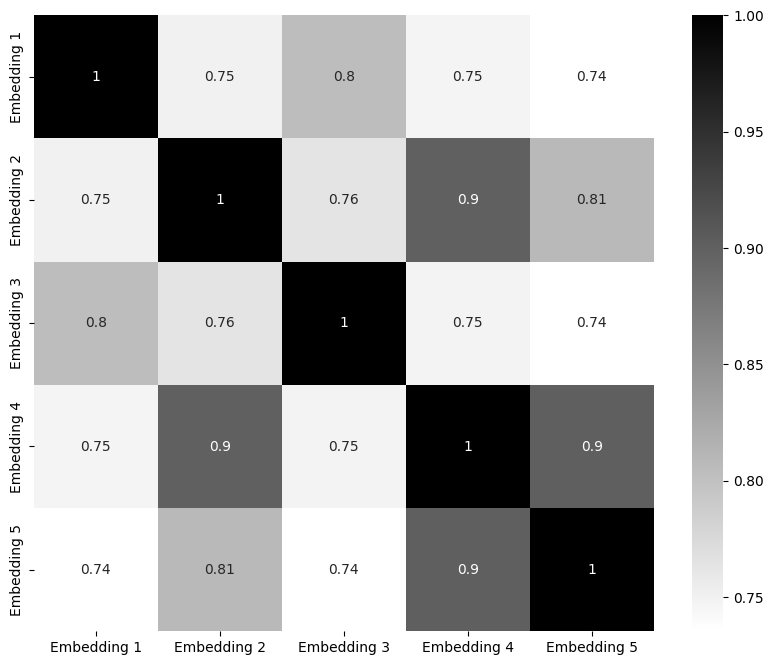
I compared the embeddings of these sentences:
sentence1 = "lakjsdfljsdaflkjasdlkfj"
sentence2 = "I love to play outside in the summer."
sentence3 = "test"
sentence4 = "I love to eat ice cream in the summer."
sentence5 = "I hate to eat ice cream in the winter."
My scenario is I have this chatbot that 1) costs the most to query the “big brains” (LLM) 2) takes the most time as the LLM hems and haws on what it wants to answer and then who knows the quality of the network…)…
Why doesn’t the retriever figure out that the index can’t answer 1 and probably “test” is not in context? and provide that feedback before traversing the LLM abiss? The challenge I have found that entering these type of queries started getting weird answers and the LLM has woken up to chat.
I’ve included the heat map for the embedding values: