I’m curious to know what is the reason to use the log function when calculating the loss/cost function? What does it give us? What would happen if we would omit it?
I think other mentor may respond from purely DL view point… ![]()
So, I’m going to explain slightly from a Math view point.
Part 1. Intuition (just like Andew ![]() )
)
As you see, in the neural network, we prepare several numbers of neurons and layers. With that, gradients sometimes become huge number or very very small number. I think you have a chance to hear the problem of “gradient explosion” and “vanishing gradient”. An example of “explosion” is like;
10 → 1000 → 100000 → 1e7 → 1e44
But, if you use log function, those are
2.3 → 6.9 → 9.21 → 16.2 → 101.3
Looks very stable.
Same to the very small number. (Then, Part 2 follows, after my short break…)
Part 2. Mathematical stability
I prepared an example by Python. As a gradient goes to very large or small value, a computer may not be handle due to its digits. It can easily return 0 or NaN. Here is an example.
Let’s consider two Gaussian distributions, and get probability densities from those. (It can be seen “slightly complex”, but what I want to do is to create a vary small number with using commonly used distributions.)
A probability density of Gaussian distribution is defined as follows.
f(x) = \frac{1}{\sqrt{2\pi\sigma^2}}exp(-\frac{(x-\mu)^2}{2\sigma^2})
Then, we create two values, a and b.
“a” is from a Gaussian distribution of (\mu=0, \sigma=1), and
“b” is from a Gaussian distribution of (\mu=1, \sigma=1)
Then, we print the value of a and b. In addition, we calculate c = \frac{a}{a+b}.
- case 1 : x=1 which means a probability density which is close to the center
- case 2 : x=50 which means a probability dencisy which is far from the center (a and b become very close tor 0)
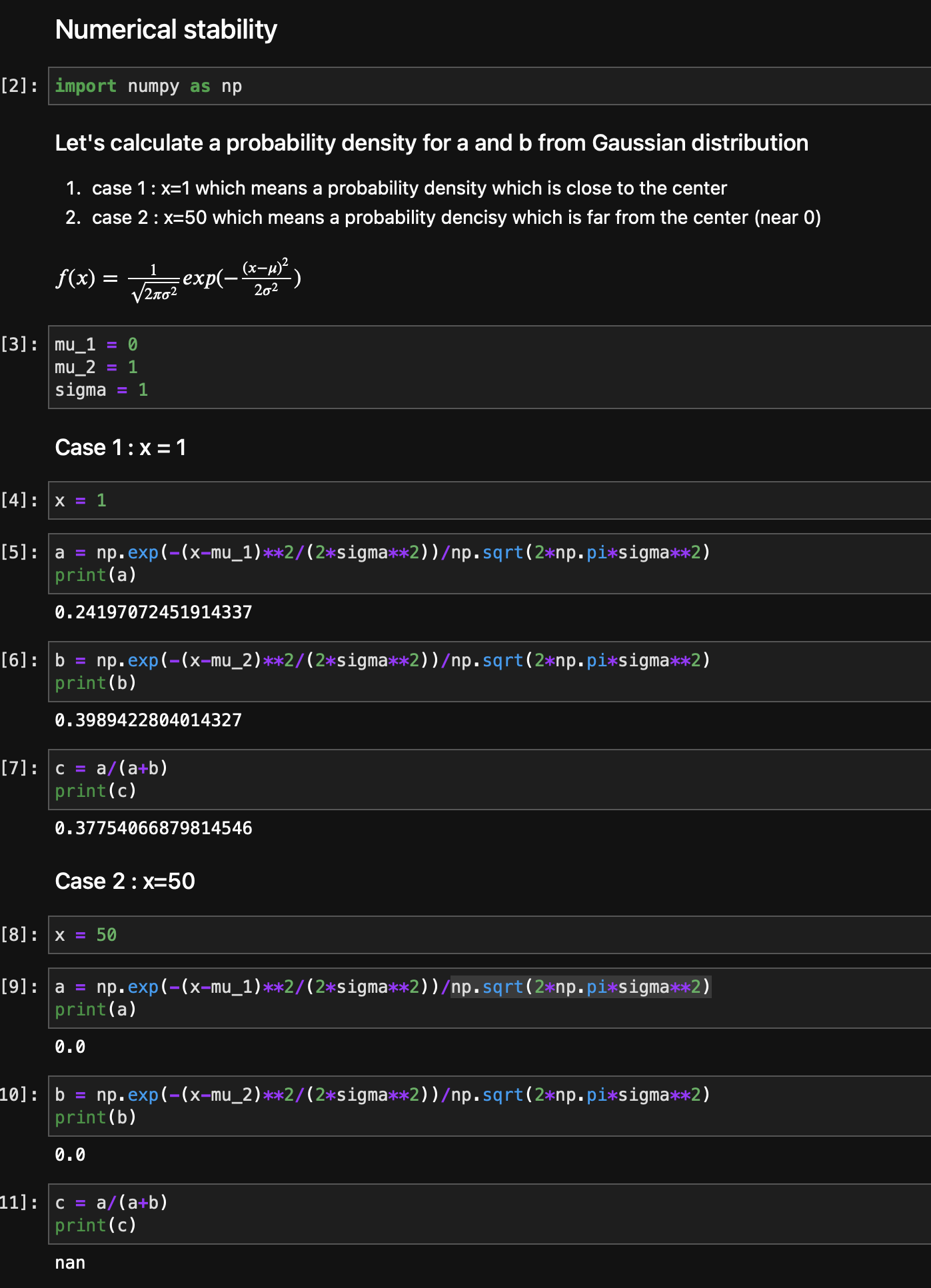
As you see, it works for the case 1, x=1. But, both a and b become 0 in the case of x=50, and c=NaN.
This is NOT an expected result, since both a and b should have a very very small number, not “0”. In this sense, c should not be NaN.
This kind of problem easily occurs in loss/gradient calculation for a deep neural network.
Then, let’s see how log works.

If we apply log to a, the value is -Inf, since the real value of a is already lost. Then, let’s apply log for a Gaussian distribution.
log(f(x)) = log(\frac{1}{\sqrt{2\pi\sigma^2}}exp(-\frac{(x-\mu)^2}{2\sigma^2})) = (-\frac{(x-\mu)^2}{2\sigma^2}) - log(\sqrt{2\pi\sigma^2})
Then, as you see in the above screenshot, both log(a) and log(b) can be calculated. Yes, we do have values that can be used for further calculation !
But, there is still a problem in calculating c. This is purely numerical stability problem.
Here is one way to get c by introducing another variable d.
exp(log\_a - d) = exp(log\_a)/exp(d)
\frac{a}{a+b} = \frac{exp(log\_a)}{exp(log\_a) + exp(log\_b)} = \frac{exp(log\_a - d)}{exp(log\_a - d) + exp(log\_b - d)}\ \ \ (since exp(d) is cancelled.)
In the case of above, we set d = max(log\_a,log\_b)
With this, we could calculate c=\frac{a}{a+b}
It is 3.1799709001977496e-22. Yes, very small number. But, this is quite important as a gradient can be easily disappeared.
Last two cells are just showing subtracting d does not affect anything with using x=1 case.
I did not want to make this long, but, just in case of someone is interested in a mathematical stability and how log works.
3 Likes
Thank you for the extensive reply!
That absolutely makes sense ![]()
Nobu has given great and very concrete examples of how the cross entropy function behaves and why it works well. Maybe the other high level thing worth saying here is that this is not just some magical thing that Machine Learning people pulled out of a hat and discovered that it worked pretty well. It is based on fundamental math and statistics that go into the concept of Maximum Likelihood Estimation in statistics which long predates the advent of Machine Learning. If you want more of the theory behind that, here’s one place to start.
2 Likes