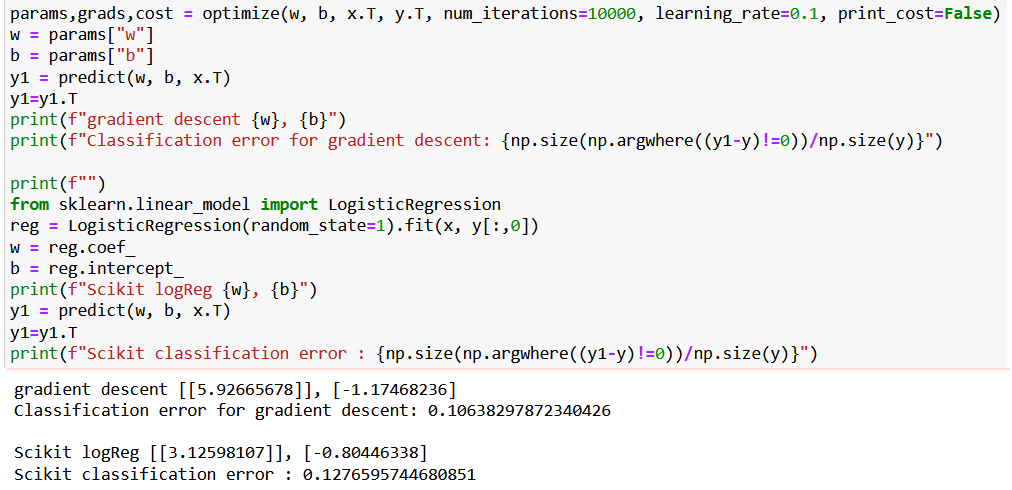
Let me pleaase ask a question. I noticed that sometimes application of sklearn logistic regression provides other set of parameters (w,b) and worse classification results than the logistic regression algorithm given in this course by prof. Andrew.
How can this can be explained, especially if the cost function has only one local minimum?
My best regards,
Vasyl
One needs to see the scikit implementation to answer it clearly, maybe the training iterations is smaller there or there is a parameter to be set for those in the scikit function.
Thank you very much for the answer.
I tried to change the number of iterations - no essential improvement. However, when I changed solver type to ““liblinear”” , the classification error became the same as for “manually written gradient descent algorithm”, though the parameters w,b were different.
I see, there must some kind of different approach with the other settings…