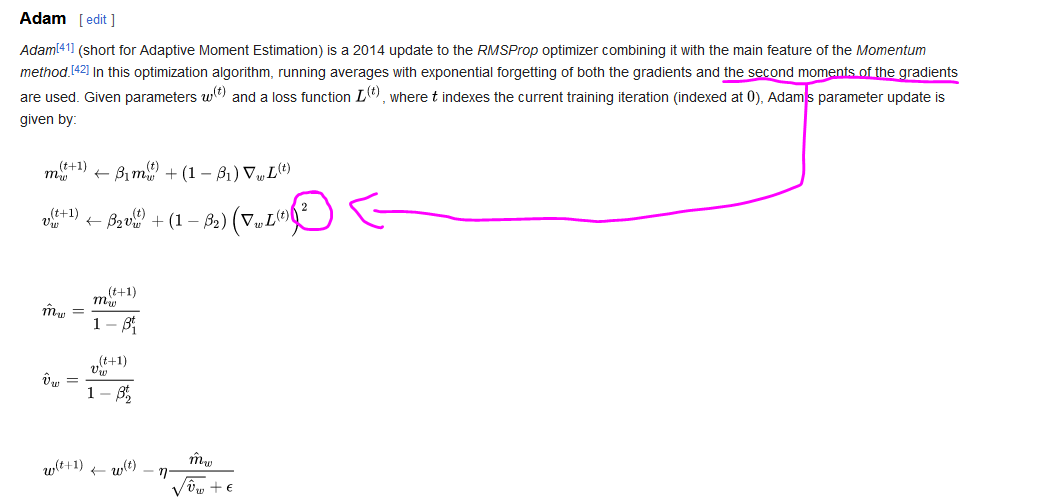
Clarification about Upcoming Adam Optimization Video
Please note that in the next video at 2:44, the following picture is correct. However, later in the video, the db² lost the ²
I searched and found this thread about the elusive t, which is close to my question so I won’t start another thread.
Here’s my question: the input parameter t is never referenced within the body of the update_parameters_with_adam() method, so why is t even there? It is also declared and assigned a value in the model() method, which calls update_parameters_with_adam(), but again I don’t see why the t is even there.
Am I missing something in the code? Thanks.
If you are not using t in your update_parameters_with_adam function, then that is a bug. Please take another careful look at the formulas as they are given both in the lectures and in the notebook. The version in the notebook is pretty small, so it’s hard to read, but maybe it would help to use your browser to “zoom in” on that image to see where the t is used in several places as an exponent.
Thank you so much! What fooled me is my code passed all tests, but the testing parameters must be setup in such a way that my bug was not detected. Next time I’ll put on better glasses so I can see things like the little t. Again, thanks for the quick response.
Interesting. It’s always difficult to write test cases that cover all possible errors, but this is a pretty critical one. I will take a look and try to understand why the test cases miss that mistake. Maybe we can suggest improvements to the test cases.
So some good may come out of your experience in addition to the lesson about having your reading glasses handy.
Great. To help you - I originally misread the t as a 2, so I was squaring the biases. As I mentioned, it passed all tests and when I submitted for grading I received 100%. I have since corrected the code, and it still passes the tests. Thanks again for your help.
Thanks for the additional information. I checked and it’s exactly that they use t = 2 as the one test case in the notebook. And apparently the grader must use the same value.
The actual training should come out differently with your implementation, but they don’t really have a test for that case.