In video Professor Andrew Ng said, The softmax regression algorithm is a generalization of logistic regression.
How can the logistic regression model with sigmoid function be derived from Softmax regression model?
Thanks and best Regards
Liyu
In video Professor Andrew Ng said, The softmax regression algorithm is a generalization of logistic regression.
How can the logistic regression model with sigmoid function be derived from Softmax regression model?
Thanks and best Regards
Liyu
Hi @liyu,
Consider we use softmax to predict a binary target, we need 2 neurons in the output layer representing the chance for target = 0 and target = 1. Let’s say their output values are z_1 and z_2 respectively,
softmax(z_1, z_2)_1 = \frac{\exp{(z_1)}}{\exp{(z_1)} + \exp{(z_2)}} = \frac{1}{1 + \exp{(z_2 - z_1)}} = sigmoid(z_1 - z_2)
Cheers,
Raymond
oh, yes! Thanks Raymond!
Liyu
Hi @rmwkwok,
Could you explain how sigmoid (z1-z2) is equivalent to sigmoid(z1)?
Hello, @tamalmallick,
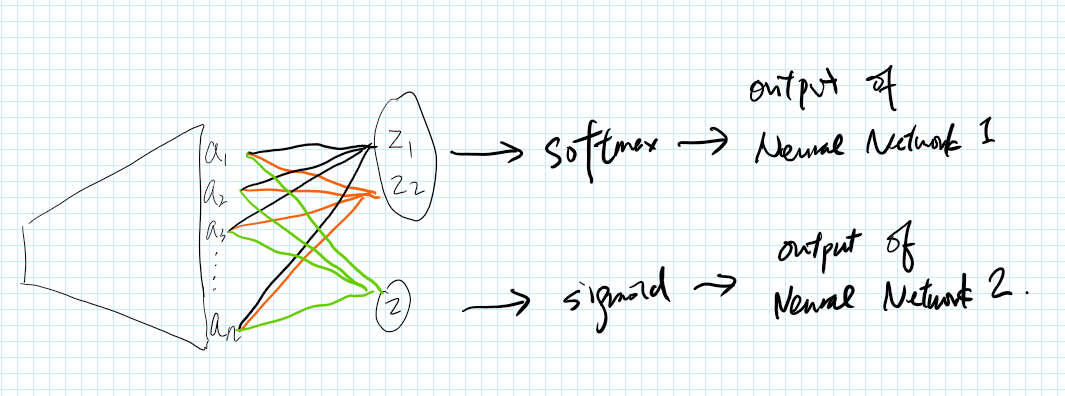
Let’s consider two neural networks sharing the same base network but different heads which are, respectively, softmax layer and sigmoid layer.
My arguments of sigmoid(z_1-z_2) and sigmoid(z) being equivalent are that -
z_1 is a linear combination of a_1, a_2, ..., a_n, and so is z_2
\implies z_1 - z_2 is a linear combination of a_1, a_2, ..., a_n
Because z is also a linear combination of a_1, a_2, ..., a_n, z and z_1 - z_2 are equivalent.
Cheers,
Raymond
hi @rmwkwok,
True, both of them are linear. Should the values of both linear expressions necessarily be the same?
Hello, @tamalmallick,
For the sake of discussing your last question, let me make two changes to my previous result/graph:
previously, I had softmax(z_1, z_2)_1 = sigmoid(z_1 - z_2), now I have softmax(z_1, z_2)_2 = sigmoid(z_2 - z_1) which predicts the probability of being class 1.
given the new equation above, I add a new branch to my previous graph for a new neural network 0:
Now, if we build neural networks 0 and 1 and initialize them to the same set of weights, and we train them, then we will get very similar set of weights at the end for network 0 and 1. I say “very similar” instead of “the same” because any intermediate numerical round-offs may accumulate into some very small difference. You might really just build them in Tensorflow and let them go through the same training procedure, then look at the trained weights. ![]()
If you are interested to give the following question a try, what about networks 0 and 2, what conclusion can we make about them?
Cheers,
Raymond